

Eval First Development: Ship Robust AI Products at Scale

Hey I'm Samiksha Kolhe. a Data Enthusiast and aspiring Data Scientist. One day Fascinated by a fact that "We can built Time machines and predict future using AI". That hit my dream to explore the Vector space and find out what the dark matter is about. World and Technology every day brings new challenges, and new learnings. Technology fascinated me, I'm constantly seeking out new challenges and opportunities to learn and grow. A born-ready girl with deep expertise in ML, Data Science, and Deep Learning, generative AI. Curious & Self-learner with a go-getter attitude that pushes me to build things. My passion lies in solving business problems with the help of Data. Love to solve customer-centric problems. Retail, fintech, e-commerce businesses to solve the customer problems using Data/AI. Currently learning MLops to build robust Data/ML systems for production-ready applications. exploring GenAI. As a strong collaborator and communicator, I believe in the power of teamwork and diversity of thoughts to solve a problem. I'm always willing to lend a helping hand to my colleagues and juniors. Through my Hashnode blog, I share my insights, experiences, and ideas with the world. I love to writing about latest trends in AI and help students/freshers to start in their AI journey. Outside technology I'm a spiritual & Yoga person. Help arrange Yoga and mediation campaigns, Volunteering to contribute for better society. Love Travelling, Reading and Learn from world.
Hello Techies👋! I’m Samiksha, Hope you all are doing amazing stuff. I’m back with Another Super trendy shift in building Agentic AI products i.e Eval first Thinking. Everyone nowadays talking about LLM-as-Judge for evaluating the Stochastic Agents or RAG’s. Let’s understand it in deeper with all aspects, This will help you built your first Eval for your usecase.
Motivation: While building a production-grade extraction system at scale, I realized that improving accuracy alone wasn’t enough. A robust evaluation layer—especially LLM-as-Judge—significantly reduced debugging time, accelerated issue resolution, and provided real-time visibility into accuracy and reliability for stakeholders.
Agenda
Introduction to LLM-as-Judge
When should you use LLM-as-Judge?
Best Practices to built the Evaluators
Five key components to build LLM-as-judge
Step by Step process to built Eval (LLM-as-Judge)
Best practices and Tips to improve Judge performance
Examples for 5 companies builted LLM Evaluators at Scale in Production
Materials to learn and built Best Evaluators.
References and inspiration for this article are taken from existing great Blogs from Hamel Hussain and technical articles, restructured and explained for clarity and understanding in this Blog.
What is LLM-as-Judge?
LLM-as-a-Judge refers to using LLMs to evaluate various components of AI systems. The methodology involves prompting a powerful LLM to assess the quality of diverse input and output, including those generated by other models or human annotations.

How is this approach going to be useful? There are times when statistical comparisons with ground truth are insufficient or downright impossible, such as when ground truth is unavailable or when unstructured outputs lack reliable evaluation metrics. The versatility of LLM-as-a-Judge stems from its reliance on well-crafted prompts, leveraging their capabilities to address virtually any question. Say you’re developing an AI that generates customer service responses. Statistical metrics like response time or keyword matching won’t capture whether the response is actually helpful or empathetic.
Using an LLM as a judge, you could evaluate things like:
Does the response address the customer’s underlying concern?
Is the tone appropriately professional yet friendly?
Does it handle cultural nuances well? • Would this likely lead to customer satisfaction?
Let’s see a sample RAG Evaluation system below:
Here’s how Incorporating the LLM-as-a-Judge method will apply to Retrieval-Augmented Generation (RAG) evaluation:
You could create a template containing retrieved chunks and a question.
then ask the LLM to determine whether the chunks are relevant for answering the question.
By providing the LLM with context chunks and an answer, you can ask it to verify whether the answer is grounded in the given context or if it introduces new factual information not present in the chunks

Before Building an Evaluator for your application Analyse your usecase based on below criterias
When should you Consider LLM-as-Judge?
If you plan on using LLM-as-a-Judge as an evaluation technique, you can use these questions to arrive at a decision.
| 1. Nature of the Task Ask yourself: 1. Is the output primarily subjective (like writing style, tone, or creativity)? 2.Does evaluation require understanding complex context or nuance? 3.Would traditional metrics (like BLEU or ROUGE) miss important qualitative aspects? | 2. Scale Requirements: Consider your evaluation needs: 1.Do you need to evaluate thousands of responses quickly? 2. Is manual human evaluation impractical due to volume? 3.Do you need consistent evaluation criteria across many samples? | 3. Cost-Benefit Analysis Evaluate the tradeoffs: 1.Is the cost of LLM API calls justified compared to human evaluation? 2. Do you need rapid iteration in development? 3. Can you leverage smaller, more efficient models for initial screening? |
| 4. Complexity of Evaluation Criteria Most suitable when: 1.Multiple aspects need simultaneous evaluation (coherence, relevance, accuracy) 2.Evaluation requires cross-referencing with context or background knowledge. 3.Judgments need to balance competing factors | 5. Best Use Cases LLM-as-a-Judge is particularly effective for: • Content generation quality assessment • Conversational AI response evaluation • Document summarization accuracy • Style and tone consistency checking • Context-aware fact-checking • Creativity and innovation measurement | 6. When To Avoid Consider alternatives when: 1 Ground truth exists and objective metrics suffice 2. Binary correct/incorrect judgments are needed 3. Extremely high stakes decisions are involved 4. Legal or compliance verification is required 5. Perfect accuracy is critical |
I personally follow below diagram while building an evaluator for any feature for my usecase.

If all the Above Answers are “Yes“, then It’s Important to leverage LLM-as-Judge for your usecase.
Iterating Quickly == Success
Like software engineering, success with AI hinges on how fast you can iterate. You must have processes and tools for:
Evaluating quality (ex: tests).
Debugging issues (ex: logging & inspecting data).
Changing the behavior or the system (prompt eng, fine-tuning, writing code)
If you streamline your evaluation process, all other activities become easy
NOTE: This article is inspired by and curated from insights shared in the Hamel Hussain Blog regarding Critique Shadowing technique for LLM-as-Judge: https://hamel.dev/blog/posts/llm-judge/#how-do-you-phase-out-human-in-the-loop-to-scale-this, adapted to present the concepts in a more practical and relatable manner for readers here.
Best Practices to Build an Evaluator:
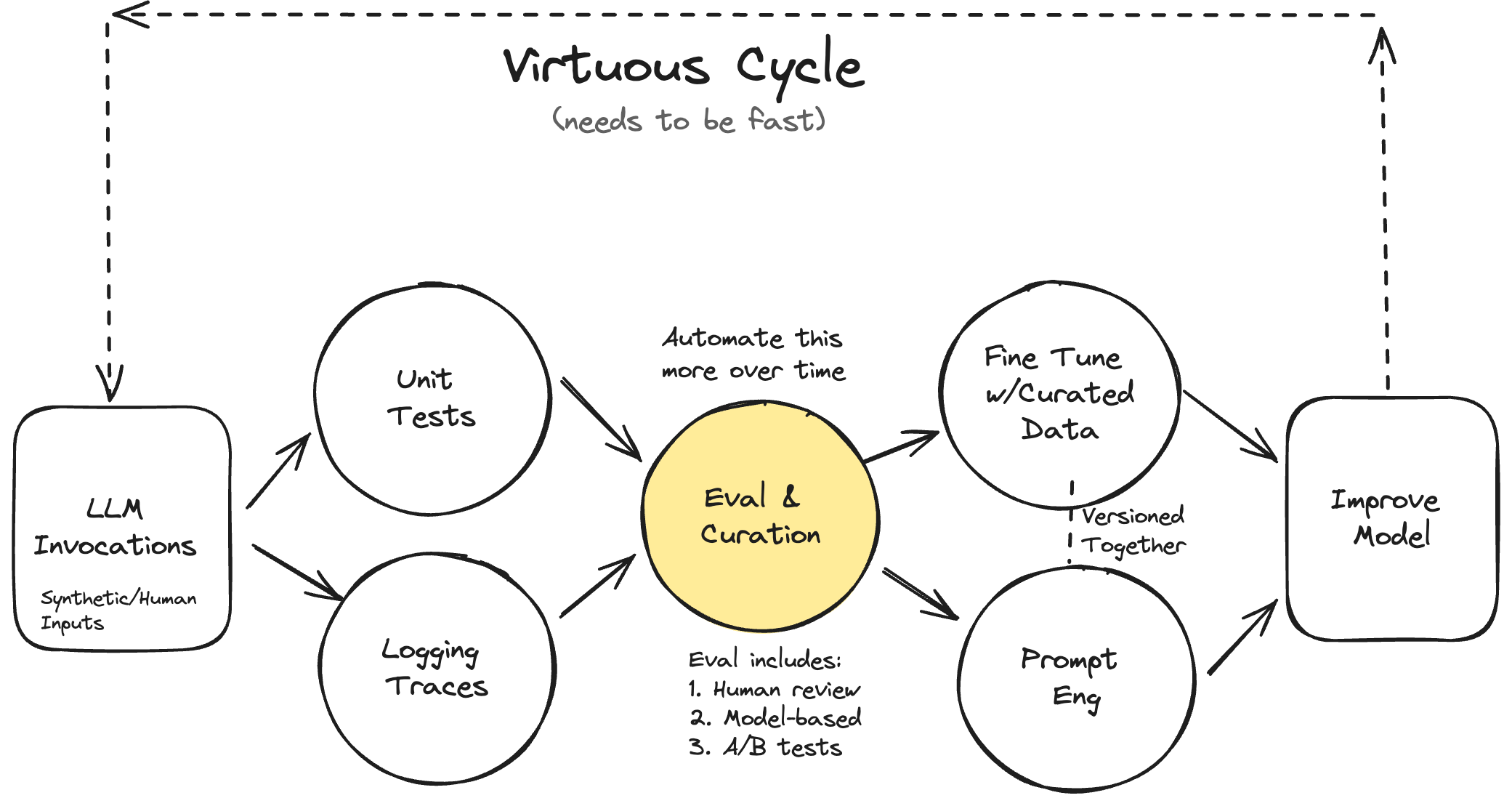
In order to Built Robust Evaluator for your AI-native Application, We should think from an Evaluator first approach. We must consider some pre-requisites, if followed will help you iteratively built an evaluator system with faster Iteration for your AI-native application.
Leverage Principle Domain Expert is Non-Negotiable: For your use case, whose judgment is crucial for the success of your AI product. These are the people with deep domain expertise or represent your target users. Identifying and involving this Principal Domain Expert early in the process is critical.
Logging and Monitoring traces: During the Application development, efficient logging to have visibility to every part of your application and traces are crucial during Data Collection and Error Analysis.
Understand the Best suited evaluator for your AI Application: There can be simple evaluators can be integrated as a part of your CI system
There are three levels of evaluation to consider:
Level 1: Unit Tests
Level 2: Model & Human Eval (this includes debugging)
Level 3: A/B testing.
The cost of Level 3 > Level 2 > Level 1.
Level 1 Unit tests: Unit tests for LLMs are assertions (pytests in Software terminology)
The most effective way to think about unit tests is to break down the scope of your LLM into features and scenarios, These unit tests are crucial to getting feedback quickly when iterating on your AI system (prompt engineering, improving RAG, etc.). Many people eventually outgrow their unit tests and move on to other levels of evaluation as their product matures, but it is essential not to skip this step!
NOTE: per application one can have 100’s of Unit tests and update them based on new failures we observe in the data as users challenge the AI or the product evolves
Writing scoped tests native to your usecase
Leverage LLM’s to generate Test cases
Running and tracking your test cases Regularly.
.. are the iterative steps to follow for building unit-tests. These unit-tests helps to reduce failure modes in the System and easy to built and maintain, than more complex Judges to maintain.
Level 2: Model & Human Eval
This is where real LLM evaluation system building comes into the picture. A prerequisite to performing human and model-based eval is to log your traces. tracing is a logical grouping of logs. In the context of LLMs, traces often refer to conversations you have with a LLM.
Searching, filtering, and reading traces are essential features for whatever solution you pick.
Having good traces helps to have more control over the Non-controlled Non-deterministic system, helps to better debug the system and the model behaviour.
Level 3: A/B testing
A/B testing is a fundamental methodology used to compare two or more versions of a product, feature, or system to determine which performs better. systematically comparing the performance of different LLMs or versions of the same LLM.
this stage off until we are sufficiently ready and convinced that our AI product is suitable for showing to real users. This level of evaluation is usually only appropriate for more mature products.
- Collect Golden Dataset: With your principal domain expert on board, the next step is to build a dataset that captures problems that your AI will encounter. It’s important that the dataset is diverse and represents the types of interactions that your AI will have in production.
Let’s discuss in detail the Best Practices to built a Golden Dataset for your Evaluation System.
Create Golden Dataset:
As an Agentic Developer, While building an Agentic system, The first step is to Analyze as much data as possible and then on top of that we should make a multi-agent workflow building decision. Hence “Collecting as much data as possible” is crucial to built a Robust evaluator.
Collecting Diverse Eval data, Consider Happy Paths, Edge cases, Error Conditions, User Variations makes evaluator align better.
When starting fresh building an Evaluator - Prefer start with Synthetic data, Once the users start using your product, built a dataset collector Agent or log traces which further you can use as Production data.
Dimensions for Structuring Your Dataset:
You want to define dimensions that make sense for your use case.
Features: Specific functionalities of your AI product.
Scenarios: Situations or problems the AI may encounter and needs to handle.
Personas: Representative user profiles with distinct characteristics and needs.
To build your dataset, you can:
Use Existing Data: Sample real user interactions or behaviors from your AI system.
Generate Synthetic Data: Use LLMs to create realistic user inputs covering various features, scenarios, and personas.

How much Data to Look at?
keep generating more data until you feel like you have stopped seeing new failure modes. The amount of data I generate varies significantly depending on the use case. There’s a concept in Qualitative data analysis i.e. “Theoretical Saturation“ - i.e. Iterate till you don’t feel we are improving or not learning new things.
Approaches for Scoring/Annotation for Evaluation Dataset:

There are 3 approaches for annotating an evaluator and the model deployment for that matter of the fact
- Single Output Scoring without reference: Single Output Sourcing (Without Reference) is particularly useful for straightforward evaluations where the quality of the output can be assessed independently.
Example:
Output to evaluate: “I understand your frustration with the delayed delivery. Our team is working on your order, and you’ll receive a tracking number within 24 hours.”
Scoring criteria (1-3):
1. Unprofessional or dismissive
2. Professional but incomplete resolution
3. Professional, empathetic, and provides clear resolution.
The LLM would score this as 2 since it’s professional but doesn’t fully address potential compensation or specific reason for delay.
- Single Output Scoring with reference: This approach builds upon the first method by incorporating additional context. The additional context could be “expected output“, “reasoning steps“. Single Output Scoring (With Reference) can lead to more nuanced and informed evaluations, especially for complex outputs
Output to evaluate: “The new environmental law requires companies to reduce carbon emissions by 30% by 2030.”
Reference text: “The Environmental Protection Act of 2024 mandates a 30% reduction in carbon emissions for companies with over 500 employees by 2030, with annual progress reports required.”
Scoring criteria (1-4):
1. Inaccurate information
2. Partially accurate but missing key details
3. Accurate but incomplete
4. Complete and accurate match with reference.
The LLM would score this as 3 since it captures the main point but omits the company size requirement and reporting details.
Pairwise Comparison: The Pairwise Comparison paradigm involves a direct comparison between two outputs. Pairwise comparison method is particularly effective for relative assessments, such as determining which of two responses is more relevant or comprehensive.
The judge LLM is presented with two inputs and asked to select the superior one based on specified criteria. It helps mitigate some challenges associated with absolute scoring, as the LLM only needs to make a comparative judgment.
| Description A: “Our wireless headphones offer 20-hour battery life and noise cancellation.” | Description B: “Experience uninterrupted music with our wireless headphones, featuring 20-hour battery life, advanced noise cancellation, and comfortable memory foam ear cups.” |
The LLM judges Description B as superior because it provides more specific features and benefits while maintaining clarity and engagement.
Now you understood, how to collect the data, for example: If your usecase is an Conversational AI chatbot. your data should be QA pairs, model critique, domain_expert/ground_truth response, domain_expert_critique. adding Critique helps during synthetic data generation and can be added in the LLM-as-Judge prompt for performance improvement.
Below is the best dataset example from Hamel Hussain’s blog, which emphasize on “importance of Critique“.
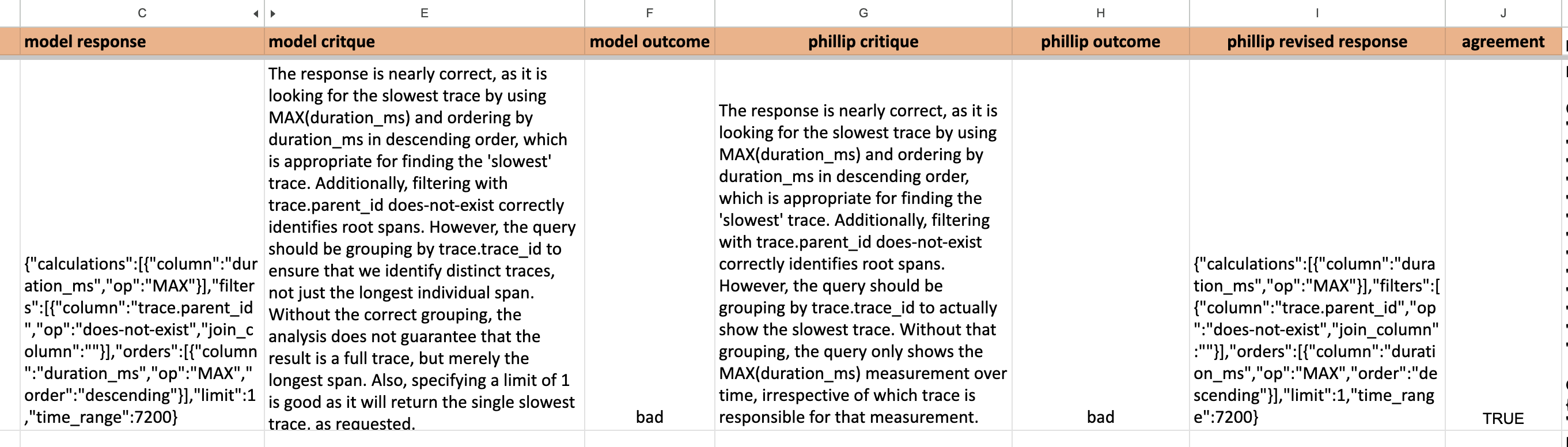
Now We are clear with First always starts with Simple i.e. Unit tests to lower down code/failure modes for less complex pain points of your application → then for more complex KPI’s work on LLM-as-Judge technique and then with more robust techniques implemented further for more complexity as per business requirements work on A/B testing.
Let’s now see for more Complex API’s how to approach LLM-as-Judge
Five Key Components for LLM-as-Judge
Building an effective LLM-as-a-Judge system involves five key components that work together to create reliable, scalable evaluation
Error Analysis: Determine the Evaluation Approach
The foundation of your LLM judge lies in choosing the right evaluation approach. This involves more than just picking between ranking and scoring. You’ll also need to make sure you’re designing an evaluation system that aligns with your specific needs.
Error Analysis totally relies on how you look at your data, Best ways to do Error analysis are as follows
Look at your logs data, collect as much traces as possible - No shortcuts.
Understand and extract the failure modes in the product/system logs.
Categorize those errors in between categories
Crafting an effective LLM-as-a-Judge system begins with determining the most appropriate evaluation approach.
This initial decision involves choosing between ranking multiple answers or assigning an absolute score. If you opt for an absolute scoring system, consider what supplementary information might aid the LLM in making more informed decisions. This could include extra context, explanations, or relevant metadata to enhance the evaluation process.
Establish Evaluation Criteria:
Once you’ve determined the approach, the next crucial step is establishing clear evaluation criteria to guide the LLM’s assessment process. When comparing outputs, you’ll need to consider various factors:
• Should the focus be on factual accuracy or stylistic quality?
• How important is the clarity of explanation?
• Should the answer come only from the context given?
• Are there specific output format requirements, such as JSON or YAML, with specific fields?
• Is the response free from restricted keywords?
• Does the response answer all of the questions asked?
Define the Response Format:
This involves carefully considering how the judge LLM should rate the LLM output. When choosing an appropriate scale, it’s best to prioritize discrete scales with limited values, such as boolean (True/False) or categorical (Disagree/Neutral/Agree) options.
NOTE: Best score format must be Binary (Pass/Fail) as it helps stakeholders to actually find clear picture of the product performance.

Choose Right LLM:

Consideration of Bias Challenges:
Unlike humans, LLM models are also trained on human annotated data. Hence Bias is the common pitfall of an LLM evaluator. Below are some types of Bias concepts which are common in LLM based evaluation.

Step by step process to Build LLM-as Judge
Step1 - Error Analysis: Explore as much traces/logs of your system both from happy path and unhappy path. then Analyze the failure points by categorizing those errors. Understanding the Product in-detail and system is super crucial to built a Robust Evaluator for your Product.
Step2 - Create the prompts based on the categorise of the Errors: provide a detailed template for Judge with proper rubrics and clarity for the goal of that judge - helps built a strong foundation for the Judge. Adding few shot examples to your judge improves it’s accuracy.
Prompts templates for llm-as-Judge can be crafted by the following strucutral format
Task Description
Measuring Criteria/Metrics
Scoring Rubrics
Step3 - Create your training set : Evaluation building in LLM era is kinda same like a data science evaluation problem, where we collect as much data as possible, curate the data, preprocess it, split that into training set and testing set, iterate the model to improve set on training examples and then test it’s accuracy on test data. Exactly same process has to be done for LLM-as-Judge Eval.
Best Practice for Training Data & Test Data: Either during your initial testing with the product, have some small user base or UAT testing setup, in that UAT phase built the training set (real user behaviour + Synthetic data), For Testing data: Once you ship your product and real users started using it, Iteratively test and improve until the LLM-as-Judge aligns with Human Judgement/Alignment.
How many examples do you need?
The number of examples you need depends on the complexity of the task. According to Hamel Hussain start with around 30 examples and keep going until do not see any new failure modes. From there, keep going until not learning anything new.
Step4 - Verify the Quality of Eval trough Rapid Iterations: It’s a Human centric and manual effort Step, where iteratively develop the prompts, improve for all failure mode, make the Human and AI alignment over failure modes, Having a Principle domain expert for this process, Helps to built Robust Evals.
Step5 - Align the AI with Human handoff for LLM-as-judge outputs:
Loop back each stage in-order to built great Evals ~ Ship Amazing Products
Best Practices to Validate your LLM-as-Judge Good or Bad?
Consider validating your LLM judge like training a new employee—you need to test their capabilities, understand their strengths and weaknesses, and ensure they’re making reliable decisions. Let’s walk through this step by step.
Select Your Test Data: The foundation of effective evaluation lies in gathering representative data. Your judge will only be as good as the data you test it with, so comprehensive coverage is essential.
Many real-world applications benefit from mixed data that combines both objective and subjective elements to test different aspects of your judge’s capabilities.
Generate Test Outputs: After selecting your data, the next step is generating LLM outputs for evaluation. It’s crucial to create outputs across the quality spectrum, from excellent to poor. This should include challenging edge cases that might confound your judge, as well as varying levels of complexity and different stylistic approaches.
Choose Your Metrics: This is where you decide how to measure success. Your options include:
• For Objective Tasks: Statistical metrics like accuracy scores
• For Subjective Tasks: Human annotations to establish ground truth
• For Mixed Tasks: A combination of both approaches Think about what matters most in your context. For instance, a very high accuracy might be crucial for medical advice but less important for creative writing feedback.
Collect Your Judgments: During the judgment collection phase, run your test outputs through the validator systematically. Your evaluation should encompass all relevant criteria, and it’s important to maintain detailed records of any patterns or inconsistencies that emerge. This systematic approach helps ensure comprehensive coverage and enables meaningful analysis.
Measure Performance: Measuring the performance of your LLM-as-a-judge is a critical step in ensuring its reliability and effectiveness. This involves evaluating how well the judge performs against a set of predefined metrics. Let’s dive deeper into the key metrics you should consider:
Common Binary Eval metrics from ML world are TPR(True positive rate), FPR(False positive Rate), F1-Scores, Confusion metric, AUC-ROC Curve, Cohen’s Kappa (More efficient for LLM output evaluation).
Tricks to Improve your LLM-as-Judge
Mitigate Evaluation Biases:
| Bias | Solution |
| Nepotism Bias | Use assessments from different LLMs and average the results to balance out individual model biases. |
| Verbosity & Positional Bias | Extract relevant notes and grade them. |
| Consistency issues | Run multiple passes and aggregate the results as shown in the self-consistency paper |
| Attention Bias | Use an LLM with better performance for long context. |
| Position Bias | Vary the sequence of responses presented to the LLM to minimize position bias. |
Let’s look at one such example in more detail:
addressing nepotism bias. If you remember, when GPT-4 evaluates responses from different models, it tends to favor its own outputs. For example, given two equivalent explanations about quantum computing, it might rate its own explanation at 9/10 while giving Claude’s 7/10.
Use Multiple LLMs for Evaluation: Instead of relying on a single LLM for evaluation, use multiple LLMs and average their scores. This helps balance out individual model biases.
Perform cross-Model Evaluation: Have each LLM evaluate outputs from other models. For instance, GPT-4 evaluates Claude’s outputs, and Claude evaluates GPT-4’s outputs. This cross-evaluation can help reduce favoritism.
Enforce Reasoning:
making Judges/LLM’s show their work— breaking down their evaluation into clear steps and explaining their reasoning—we get much better results. You’re also adding self-reflection into the mix, where the LLM double checks its own work, kind of like asking, “Am I being fair here? What might I be missing?” It’s simple but effective: understand the response, analyze it piece by piece with specific examples, and then tie it all together with a well-justified conclusion. And the best part? When the LLM makes a call, you can actually understand why, making it much easier to trust (or question) its judgment.
Break Down Criteria into Components:
When evaluating complex responses, separating the assessment into distinct components yields better results.
Start with specific criteria like clarity, accuracy, and relevance, score each independently, then combine them for the final assessment. This method helps pinpoint exactly where a response excels or falls short, leading to more actionable feedback and fairer evaluations.
In this technique, you’d typically start with:
• Scoring each component independently (typically 1-5)
• Weighing components based on priority
• Calculating the weighted average for the final score A response scoring high on clarity (5/5) but low on completeness (2/5) gets a fair assessment instead of an oversimplified middle score.
This granular approach enables precise comparison between responses and helps track improvements over time.
Align Evaluations with User Objectives:
Write the prompts in such a way that it should be very personalised based on the user objective or criteria for example: for technical docs the Accuracy must be more important while assigning priority in the judge prompt, while in the Customer. service scenario, empathy must be more priotise than the accuracy, reliability etc.
Utilize Few-Shot Learning:
Your examples set the standard for evaluation. The better they represent your expectations, the more accurate your LLM judge will be at assessing new responses. Below is the sample example of few shot prompting example template for LLM-as-Judge.

Incorporate Adversarial Testing:
Your LLM judge needs to handle tricky cases well. Test it with challenging responses - by mixing excellent points with errors, try unusual formats, or include subtle mistakes. These stress tests help you spot where your evaluation system might stumble.
Implement Iterative Refinement:
Your evaluation system should get better over time. Each evaluation offers insights into what works and what needs adjustment.
What to Track: Scoring Inconsistencies, Missed Evaluation Criteria, Challenging Response Types, Conflicting Criteria. & Where to Make Improvements: Prompt Structure, Evaluation Criteria, Example Sets (Training set)
Long story Short presented below:

5 Companies which Nailed the LLM-as-Judge in the Production to Scale their AI products
Asana
They use LLM-as-a-judge method for evaluations to verify if the unit test assertions are true. To ensure accuracy, the team runs tests multiple times (e.g., best-of-3). Fast execution allows developers to iterate efficiently in sandboxes.
Asana also runs integration tests to validate multi-prompt chains before release. It helps ensure they retrieve the necessary data and generate accurate user-facing responses.
For end-to-end testing, Asana uses realistic data in sandboxed instances to reflect real-world customer interaction scenarios. These tests are graded manually by product managers. While this process takes longer, manual review allows for assessing harder-to-quantify aspects like tone and style and catching unexpected quality issues before production.
WebFlow
Webflow measures its LLM system's performance along several axes. They combine a multi-point human rating system with heuristic evaluations that check whether a specific true/false condition is being met.
As human evaluations are time-consuming and usually don’t scale well, Webflow automates them using an LLM judge that assesses the LLM system’s responses against predefined criteria. To learn more about LLM judges and how they work, check out this in-depth guide.
To check how well LLM-based evals match human evaluations, Webflow runs them side-by-side. In practice, they combine both methods. For example, they rely on automated scores for day-to-day validation and do weekly manual scoring to validate all significant changes. Webflow also relies on automated scores to detect unexpected regressions in quality.
Wix
Wix customizes an LLM to its use cases, which requires dedicated evaluation benchmarks and an extensive evaluation process. While open LLM benchmarks are useful for evaluating general-purpose capabilities, custom benchmarks are needed to estimate domain knowledge and abilities to solve domain tasks.
To estimate the LLM's domain knowledge, Wix built a custom evaluation dataset from existing customer service live chats and FAQs. To assess the quality of responses, they built an LLM judge that compares LLM-suggested answers to the ground truth.
For task capabilities estimation, Wix uses domain-specific, text-based learning tasks. These include customer intent classification, customer segmentation, custom domain summarization, and sentiment analysis.

Segment
built an LLM-powered Audience Builder that helps express query logic. For example, it allows searching for “all users who have added a product to the cart but not checked out in the last 7 days” without code. Behind the scenes, the query is expressed as an AST (abstract syntax trees).
However, evaluating the quality of generated queries is not so straightforward. For complex queries, there are multiple correct ways to express an audience. This means that you can’t simply compare the answer you get against a single ground truth answer.
To determine the best representation, Segment uses LLM-as-a-judge. The judge compares the “ground truth” – examples of queries built by the users before – to new generated outputs to assess correctness.
Additionally, the team had to solve a task of creating a test dataset. They built an LLM Question Generator Agent that takes a ground truth AST input and generates a possible input prompt. The synthetic prompts are then put into the AST Generator, and the LLM Judge evaluates the new output.

DoorDash:
Doordash, a food delivery company, built a RAG-based support chatbot to provide timely and accurate responses to Dashers, independent contractors who do deliveries through DoorDash.
To monitor the system quality over time, DoorDash uses a system that assesses the chatbot's performance across five LLM evaluation metrics: retrieval correctness, response accuracy, grammar and language accuracy, coherence to context, and relevance to the Dasher's request.
They originally performed manual evaluations of conversation transcripts, which helped them narrow down the quality criteria. They further implemented monitors that use an LLM-as-a-judge approach or a metric based on regular expressions.
The quality of each aspect is determined by prompting the judge with open-ended questions. Answers to these questions are then summarized into common issues for further analysis. DoorDash has a dedicated human team that reviews random subset transcript samples to calibrate the evaluations of the LLM judge.

Materials to learn and built Best Evaluators:
below are the Top Curated and Best Video’s, Blogs, Books which i followed while learning Evals and writing this Blog
I’m personally a Huge fan of Hamel Hussain and Shreya Shankar - They approach Eval as a systematic improvement technique to improve stochastic AI Product - emphasis on Error Analysis & Data Science approach to built a great Product with Eval first thinking.
Blogs: follow Hamel Hussain - https://hamel.dev/blog/posts/field-guide/, https://hamel.dev/blog/posts/evals/
W&B course for Evals - https://wandb.ai/site/courses/evals/
Youtube Video Recommendations: follow Hamel Hussain channel, watch below videos to give you gist of information to approach LLM Eval. follow AI Engineering youtube channel for latest AI stuff demos and real-world implementaton.
https://www.youtube.com/watch?v=BsWxPI9UM4c
https://www.youtube.com/watch?v=uiza7wp1KrE
Books: Evals for AI Engineers by Hamel Hussain and Shreya Shankar.
Hurray! We now can start building and refining our product from Eval First Approach mindset..
Here’s the End!! As an Extension of this Article, I’m going to practically implement an Eval System for one of the Extraction Usecase in-detail with Code(Next Article).. Let’s built and understand it together!
For that Stay tuned and follow our newsletter to get daily updates. Connect with me on linkedin, github, kaggle.
Let's Learn and grow together:) Stay Healthy stay Happy✨. Happy Learning!!



