

End-to-End Practical Full-stack Advance Hybrid RAG Application: AI Consultant Chatbot

Hey I'm Samiksha Kolhe. a Data Enthusiast and aspiring Data Scientist. One day Fascinated by a fact that "We can built Time machines and predict future using AI". That hit my dream to explore the Vector space and find out what the dark matter is about. World and Technology every day brings new challenges, and new learnings. Technology fascinated me, I'm constantly seeking out new challenges and opportunities to learn and grow. A born-ready girl with deep expertise in ML, Data Science, and Deep Learning, generative AI. Curious & Self-learner with a go-getter attitude that pushes me to build things. My passion lies in solving business problems with the help of Data. Love to solve customer-centric problems. Retail, fintech, e-commerce businesses to solve the customer problems using Data/AI. Currently learning MLops to build robust Data/ML systems for production-ready applications. exploring GenAI. As a strong collaborator and communicator, I believe in the power of teamwork and diversity of thoughts to solve a problem. I'm always willing to lend a helping hand to my colleagues and juniors. Through my Hashnode blog, I share my insights, experiences, and ideas with the world. I love to writing about latest trends in AI and help students/freshers to start in their AI journey. Outside technology I'm a spiritual & Yoga person. Help arrange Yoga and mediation campaigns, Volunteering to contribute for better society. Love Travelling, Reading and Learn from world.
Hello Techies👋! I’m Samiksha, Hope you all are doing amazing stuff. Welcome to another BlogCast Regarding amazing and trending stuff in the market today. The RAG(Retrieval Augmented Generation) Technique, Helps enterprises use Large Language Models efficiently to work on their business critical data without finetuning the model from scratch.
As a RAG practitioner who works with clients to improve the accuracy and performance of the RAG system, I’ll provide more insights into how to build the system with a practical, hands-on example.
Sounds Exciting!!🤩
Note: In this article, I’ve discussed the Advanced RAG Chatbot Practical Use Case using Langchain. This article is for beginners and AI engineers, as I’m going through every detail about the Naive to Advanced RAG Evolution.
This Article is mostly around Text Modality Based RAG systems, although Multi-modal RAG is ever evolving nowadays which combines Text/Image/Video/Audio.. will discuss the MultiModal RAG systems in next article!!
💡This Article is a bit longer and deeper regarding RAG through a practical Use-case builted on Consulting and audit Company Website Data. All Techniques are in place from theory to practice. All Necessary Information at One Place!!
What you'll learn from this article:
Table of Contents
Understanding the History of RAG.
Finetuning v/s RAG.
Types of RAG Systems & Architecture Evolution.
Practical Advance RAG System: Dive deep into the “AI Consultant“ Chatbot built on the EY website using Langchain.
RAG System Challenges & Practical Solutions.
RAG vs. Long Context LLMs | RAG + Long-context LM’s.
Production Ready RAG Architecture by NVIDIA.
Key-Takeways from Industry Experts on Building RAG Systems.
&& BONUS: Retrieval Augmented Fine-tuning (RAFT)
wait, Please Note, If you’re new to the GenAI terms like LLM, Prompting, in-context learning, finetuning, Embeddings, and Vectorstore etc, Then First check out my previous Articles here Before jumping on to the Article further.
Let's get into it!!
What Is RAG? How it All Started?
- Patrick Lewis, lead author of the 2020 paper that coined the term RAG.
Retrieval-augmented generation (RAG) is a technique for enhancing the accuracy and reliability of generative AI models with facts fetched from external sources. As We know LLM models are typically trained on some time-specific Data. LLM model when Ask Questions regarding Knowledge/Structured Information which the Model is not getting trained on, tends to perform Hallucinations. Hence RAG technique Helps to Reduce Model Hallucinations on Specific Use-case data. RAG involves Mainly two phases Retrieval and Generation. This technique makes the LLM model work for Domain-specific tasks and works over a particular avenue of company data.
RAG significantly impacted using the Generative AI technology for Businesses and solved the common use cases using LLM.
In other words, it fills a gap in how LLMs work. Under the hood, LLMs are neural networks, typically measured by how many parameters they contain. An LLM’s parameters essentially represent the general patterns of how humans use words to form sentences.
That deep understanding, sometimes called parameterized knowledge, makes LLMs useful in responding to general prompts at light speed. However, it does not serve users who want a deeper dive into a current or more specific topic.
Building User Trust
Retrieval-augmented generation gives models sources they can cite, like footnotes in a research paper, so users can check any claims. That builds trust.
What’s more, the technique can help models clear up ambiguity in a user query. It also reduces the possibility a model will make a wrong guess, a phenomenon sometimes called hallucination.
Another great advantage of RAG is it’s relatively easy. A blog by Lewis and three of the paper’s coauthors said developers can implement the process with as few as five lines of code.
That makes the method faster and less expensive than retraining a model with additional datasets. And it lets users hot-swap new sources on the fly.
RAG typically involves two phases, Retrieval/Search and Generation.
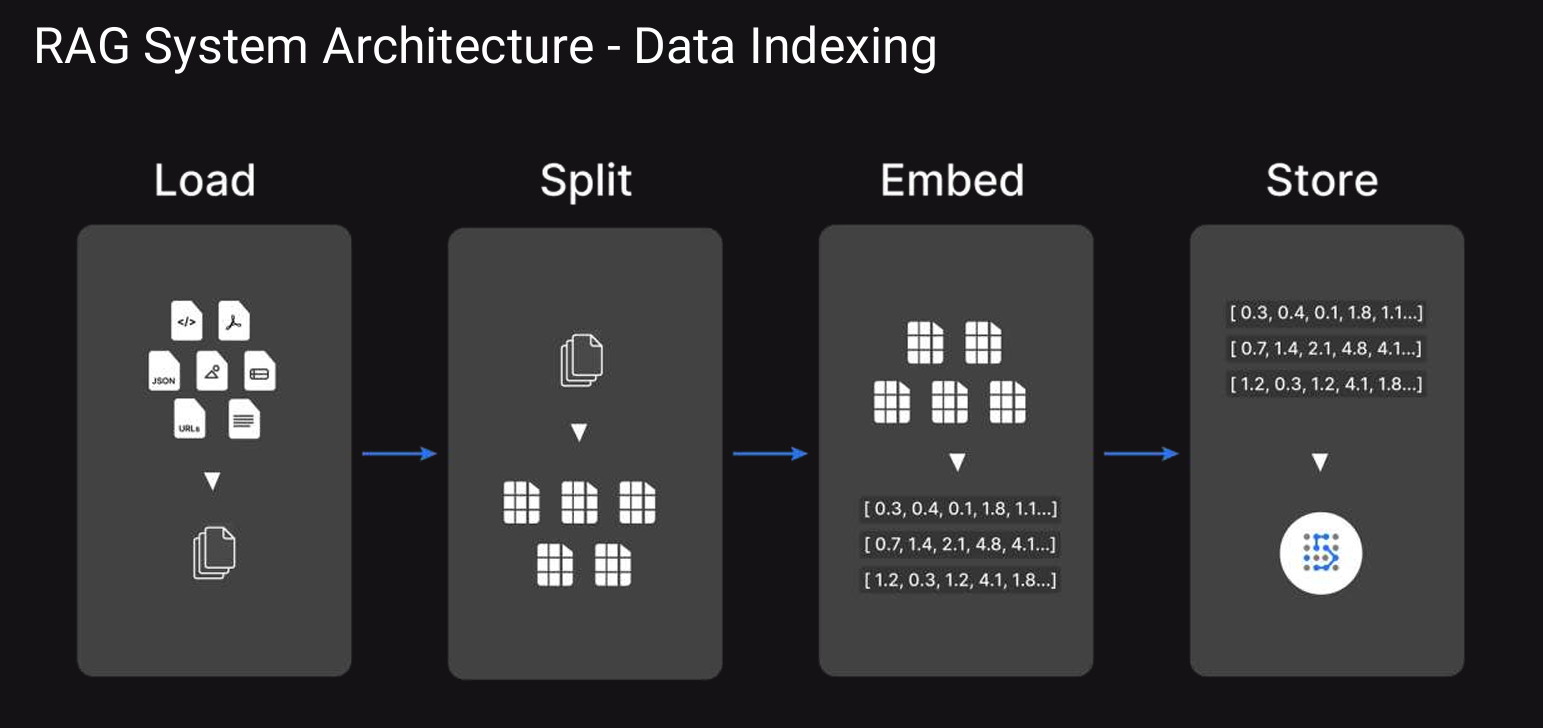
Retrieval: This is the first and very important step in generating Domain specific context which plays a crucial role in the generation phase while generating answers/Responses.
in this phase, The domain-specific data gets loaded → split into chunks → Embedded (converting text into a vector format). Your data first gets stored in a vector store.
Vector Store
A vector store is a type of Database where multi-dimensional data can be stored and indexed. A vector database indexes and stores vector embeddings for fast retrieval and similarity search, with capabilities like CRUD operations, metadata filtering, horizontal scaling, and serverless. With a vector database, we can add knowledge to our AIs, like semantic information retrieval, long-term memory, and more.. For more detailed information checkout this amazing Blog by Pinecone!
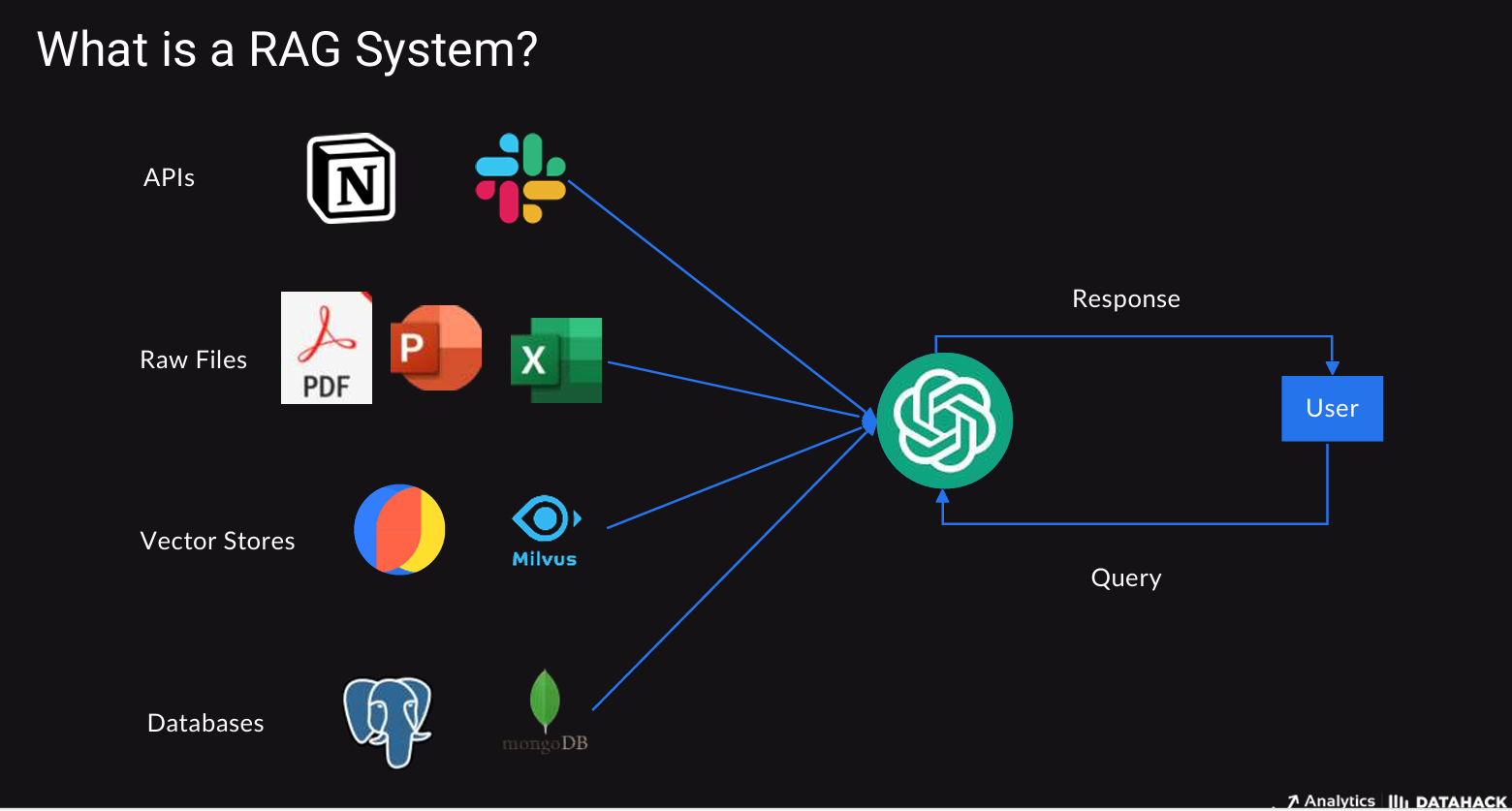
- Search and Generation: In this Phase, your question will get embedded with the embedding model same which get used for Document retrieval phase, further Based upon the question Search happens on the data present in the vector store.
From the below image you can see, the question get embedded and used for retrieval from the vector store, and similarity search results contain the relevant data retrieved based on the question, Further Question and Retrieved Context get added to the prompt. the prepared prompt will further get send to the LLM model which generates the response.
Prompt

Let’s See together how the typical RAG Architecture and System works below:!
How Retrieval-Augmented Generation Works?
- When users ask an LLM a question, the AI model sends the query to another model that converts it into a numeric format so machines can read it. The numeric version of the query is sometimes called an embedding or a vector.
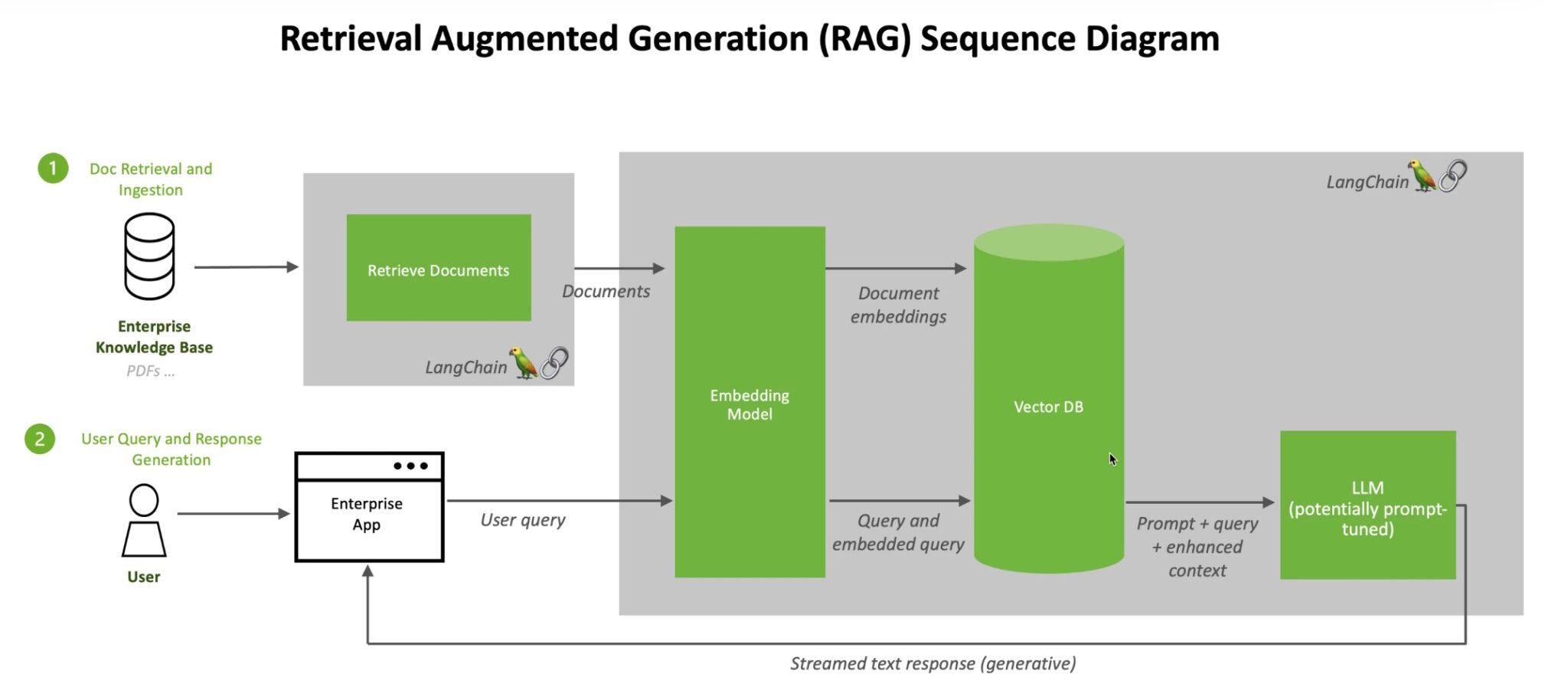
Retrieval-augmented generation combines LLMs with embedding models and vector databases.
The embedding model then compares these numeric values to vectors in a machine-readable index of an available knowledge base. When it finds a match or multiple matches, it retrieves the related data, converts it to human-readable words, and passes it back to the LLM.
Finally, the LLM combines the retrieved words and their response to the query into a final answer it presents to the user, potentially citing sources that the embedding model found.
This is how a typical Naive RAG System works and is designed. This RAG is very basic and works on Simple patterns of User queries, But as the Human Brain differs from person to person, so their pattern of Asking Questions, This RAG field evolved based on 3 main aspects described below:
- Designing RAG Systems to handle complex sets of queries.
Designing RAG Systems to Improve Accuracy, and Reduce Hallucination.
- Designing RAG Systems for Production to Reduce Failure Risk, Scalability, and Cost.
I’ve Covered the Above 3 aspects of RAG system-building principles in my Hands-on Practical Example Section below!!
Now Let’s see How the systems based on Query Complexities Evolved and How one should approach while building a POC with a client.
Fine-tuning v/s RAG
Typically, A foundation model can acquire new knowledge through two primary methods:
Fine-tuning: This process requires adjusting pre-trained models based on a training set and model weights. Finetuning involves more resources, Knowledge about Transformers, data processing, time and infrastructure to setup the system
RAG: This method introduces knowledge through model inputs or inserts information into a context window.
Fine-tuning has been a common approach. Yet, it is generally not recommended to enhance factual recall but rather to refine its performance on specialized tasks. Here is a comprehensive comparison between the two approaches:
| Category | RAG | Fine-Tuning |
| Functionality | Combines retrieval and content generation | Adapts pre-trained models to create content |
| Knowledge access | Retrieves external information as needed | Limited to knowledge within the pre-trained model. |
| Up-to-date data | Can incorporate the latest information | Knowledge is static, and challenging to update. |
| Use case | Suitable for knowledge-intensive tasks. | Often used for specific, task-driven applications. |
| Transparency | Transparent due to sourced information. | May lack transparency in decision-making. |
| Resource efficiency | May require significant computational resources | Can be more resource-efficient. |
| Domain specificity | Can adapt to various domains and sources. | Must be fine-tuned for specific domains. |
Strategies of RAG Systems: Simple to Advance
Types of RAG systems and approaches may differ as per the use case and client requirements. generally, While building any POC one needs to start building Naive RAG first, Naive RAG helps one to kickstart the process and have common systems arranged to enhance the system further. Consider the below image which shows the approaches and their effects on Cost and latency.
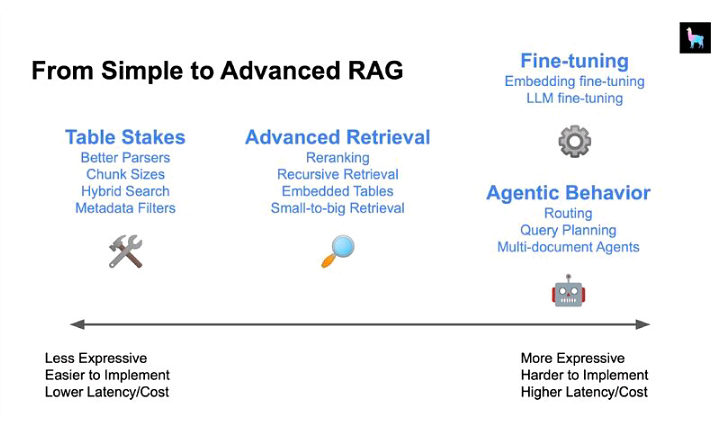
Simple RAG system: The simple RAG system consists of Research on the following Strategies:
Better Parsers: scrape or Preprocess the data, Parsers can be selected based on the type of Documents you’re dealing with. It’s crucial to select the best Parsers specific to your data requirements which contributes significantly to enhancing retrieval and semantic search during the retrieval phase of RAG.
Chunk Sizes involve experimenting with different chunking techniques to create context-aware chunks. Chunking is done with the fact of Considering the context length of the LLM model, i.e. LLM model is more
Hybrid Search: Hybrid Search involves adding
Metadata Filters:
Typically Simple RAG system involves research on retrieval strategies and hence takes Less Cost & Lower Latency.
- Advanced RAG System: Advanced RAG now encompasses primary elements, comprising pre-retrieval, retrieval, and post-retrieval methodologies.
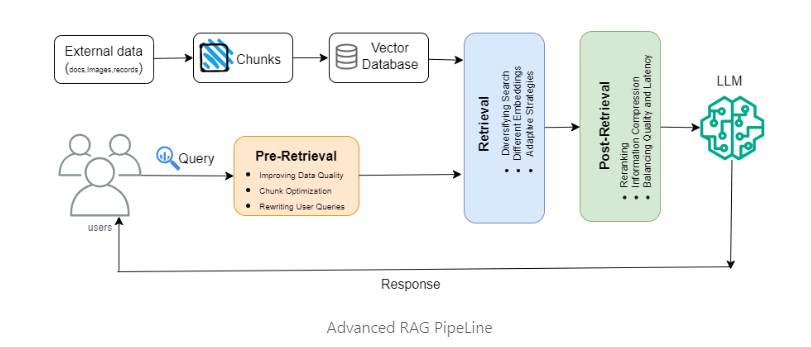
The pre-retrieval process involves optimizing data indexing which aims to enhance the quality of the data being indexed.
Techniques for Improving Pre-Retrieval Process
1.1 Improving Data Quality in the Indexing Step:
Remove irrelevant text/documents tailored to your specific task. Reformat indexed data to match end users’ expected formats. Add metadata to enhance efficient and targeted retrieval.
Example: Tagging math problems with metadata for concepts and levels.
1.2 Chunk Optimization for Varied Downstream Tasks:
Determine optimal chunk length and overlap based on downstream task requirements. Experiment with different chunk optimization methods for diverse pipeline steps.
Example: Using larger chunks for summarization and smaller ones for coding references.
1.3 Rewriting User Queries for Improved Matching
Transform user queries to a format resembling the vector database. Utilize techniques like Query2Doc or HyDE to generate hypothetical documents for improved retrieval.
Example: Generating hypothetical code documentation relevant to a user's query.
1.3.1. Sub-Query Breakdown for Complex User Queries:
Break down complex queries into multiple sub-queries for targeted retrieval.Use LLM to rephrase queries into more manageable components.
Example: Breaking down a question about two different concepts into individual queries.
1.3.2 Dynamic Query Routing for Diverse Tasks:
- Employ query routing based on downstream task requirements. Dynamically route queries to different RAG processes for specific responses.
- Example: Routing users asking for specific answers to query specific chunks.
The retrieval stage can be further improved by optimizing the embedding model itself which directly impacts the quality of the chunks that make up the context.
Techniques for Improving Retrieval:
1.1. Diversifying Search Methods:
Explore alternative search methods, such as full-text search, structured queries, and graph-based searches.Consider hybrid search approaches to complement vector similarity search.
Example: Using full-text search for specific drug names or structured queries for diverse data.
1.2. Testing Different Embeddings:
Experiment with different embedding models to capture varied semantic information. Test models like Instructor Embedding are tailored to specific tasks.
Example: Testing multiple embeddings and selecting the one most suited for the task.
1.3 Adaptive Retrieval Strategies:
Implement small-to-big or recursive retrieval to provide contextually relevant information. Use hierarchical retrieval for efficient filtering of irrelevant documents.
Example: Retrieving summaries first and then searching for specific chunks within those summaries.
post-retrieval focuses on avoiding context window limits and dealing with noisy or potentially distracting information. A common approach to address these issues is re-ranking which could involve approaches such as relocation of relevant context to the edges of the prompt or recalculating the semantic similarity between the query and relevant text chunks
Techniques for Improving Post-Retrieval Process:
1.1 Reranking or Scoring:
Implement a second round of reranking or scoring to prioritize relevant text chunks. Use LLM or other methods like keyword frequency for refined selection.
Example: Asking the LLM to rank relevance before generating a final answer.
1.2 Information Compression for Multiple Chunks:
For tasks involving multiple chunks, compress information through summarization or keypoint extraction. Pass aggregated, condensed information to the LLM for more efficient generation.
Example: Summarizing or extracting key points before generating a comparison response.
1.3 Balancing Quality and Latency:
1.3.1 Using Smaller, Faster Models:
Employ smaller, faster models for certain steps in the RAG process to improve latency. Assess the trade-off between model size and generation quality.
Example: Using a smaller local model for easy query rewriting or summarization.
1.3.1 Parallelizing Intermediate Steps:
Run parallel processes for certain intermediate steps to reduce overall processing time. Modify RAG frameworks or create custom pipelines for parallelization.
Example: Parallelizing hybrid searching or summarization for faster results.
1.3.2 Multiple Choices Instead of Long Text:
Opt for the LLM to provide multiple choices instead of generating lengthy text. Speed up response time by focusing on ranking or scoring information.
Example: Listing scores/ranks of text chunks instead of generating detailed explanations.
1.3.3 Implementing Caching for Frequently Asked Questions:
Cache responses for commonly asked questions to improve response time. Utilize previous answers as references for similar queries.
Example: Providing instant answers for recurring or similar queries based on cached responses.
Types Of RAG Systems: Depending Upon the Use-cases the type of RAG System differs.
For more information, check out this article.
I’ve collected some resources on the evolution of the RAG approaches during the last 1 year, Let’s discuss the Types of RAG Approaches one by one:
Contextual RAG: Contextual RAG is an enhanced version of standard RAG that adds context to each chunk of information before retrieval. It uses techniques such as contextual embeddings and contextual BM25 (Best Matching 25) to provide chunk-specific explanatory context, improving the accuracy and relevance of the retrieved information.

Query-based RAG/Normal RAG:
Query-based RAG is also called prompt augmentation. It integrates the user’s query with insights from documents fetched during the retrieval process, directly into the initial stage of the language model’s input. This paradigm stands as a widely adopted approach within the applications of RAG.
Once documents are retrieved, their content is merged with the original user query to create a composite input sequence.
- This enhanced sequence is subsequently fed into a pre-trained language model to generate responses.
Latent Representation-based RAG:
- In the framework of Latent Representation-based RAG, the generative models interact with latent representations of retrieved objects, thereby enhancing the model’s comprehension abilities and the quality of the content generated.
Logit-based RAG:
- In Logit-based RAG, generative models combine retrieval information through logits during the decoding process. Typically, the logits are summed or combined through models to produce the probability for stepwise generation.
Self-Reflective RAG:
- Requires specialized instruction-tuning of the general-purpose language model (LM) to generate specific tags for self-reflection.
Corrective RAG:
- uses an external retrieval evaluator to refine document quality. This evaluator focuses solely on contextual information without enhancing reasoning capabilities.
Speculative RAG: Improving accuracy by up to 12.97% and reducing latency by 51% compared to traditional RAG systems.
Speculative RAG is a framework that uses a larger generalist language model to efficiently verify multiple RAG drafts produced in parallel by a smaller, specialized distilled language model.
Each draft is based on a distinct subset of retrieved documents, providing diverse perspectives and reducing input token counts per draft.
According to the research, this method enhances comprehension and mitigates position bias over long contexts. By delegating drafting to the smaller model and having the larger model perform a single verification pass, Speculative RAG accelerates the RAG process.
Experiments show that Speculative RAG achieves state-of-the-art performance with reduced latency.
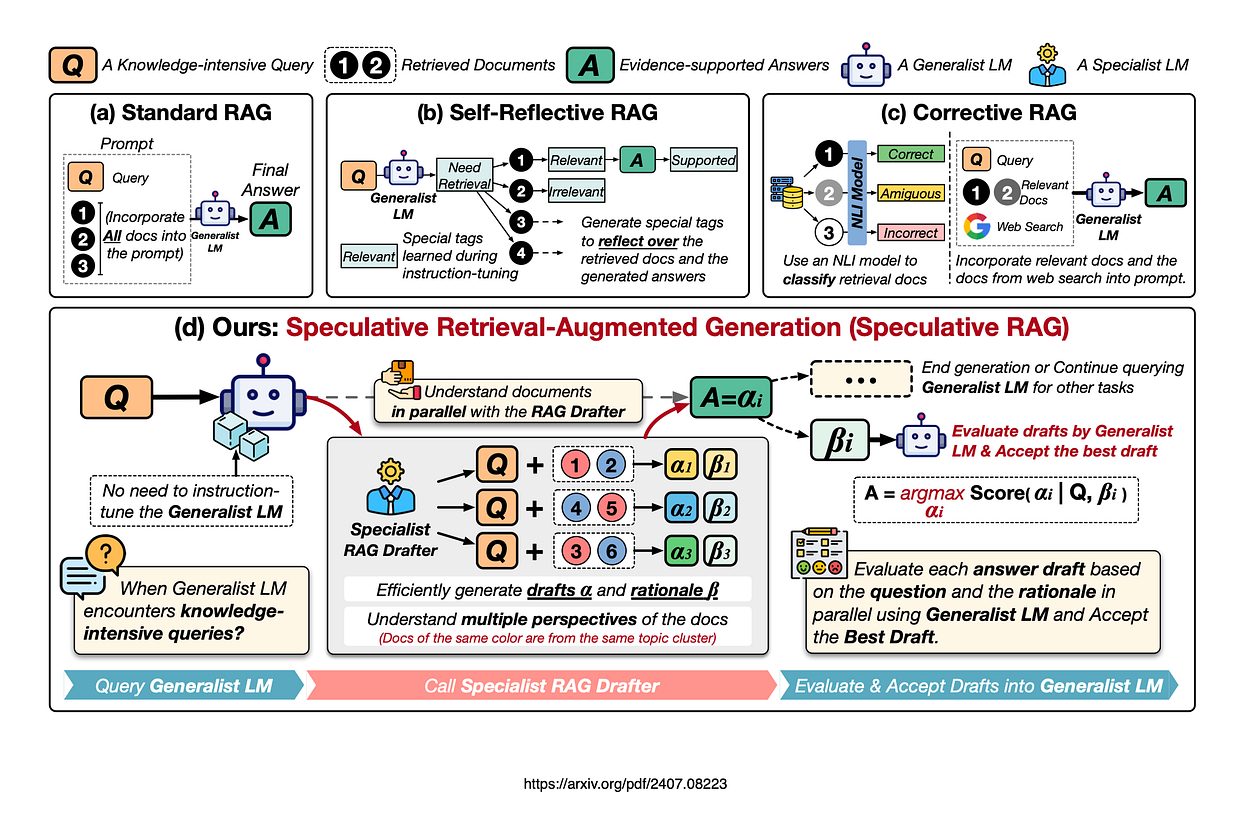
Wohhh!! Now you must be clear about the How the Evolution of RAG systems progress over the year, These Types of RAG Systems and their applicability differ from use case to use case.
Note: The best Approach to developing RAG prototypes is to Start with Naive Research. Development the RAG system as per the client feedback, and Iterative Enhancement is the best way of developing a Robust RAG System. Easier to make it to the Deployment.
I’ll discuss further building an advanced Query-based RAG System on the Blogs and articles of the EY-In Website(the Website allows crawling to anyone mentioned in https://www.ey.com/robots.txt). This Full-stack Chatbot Application was built using FastAPI and Streamlit and deployed over the Streamlit cloud. Let’s Understand approaches and Lessons while enhancing the Chatbot performance.
Practical Hands-on Advance Hybrid RAG: AI Consultant Chatbot🤩
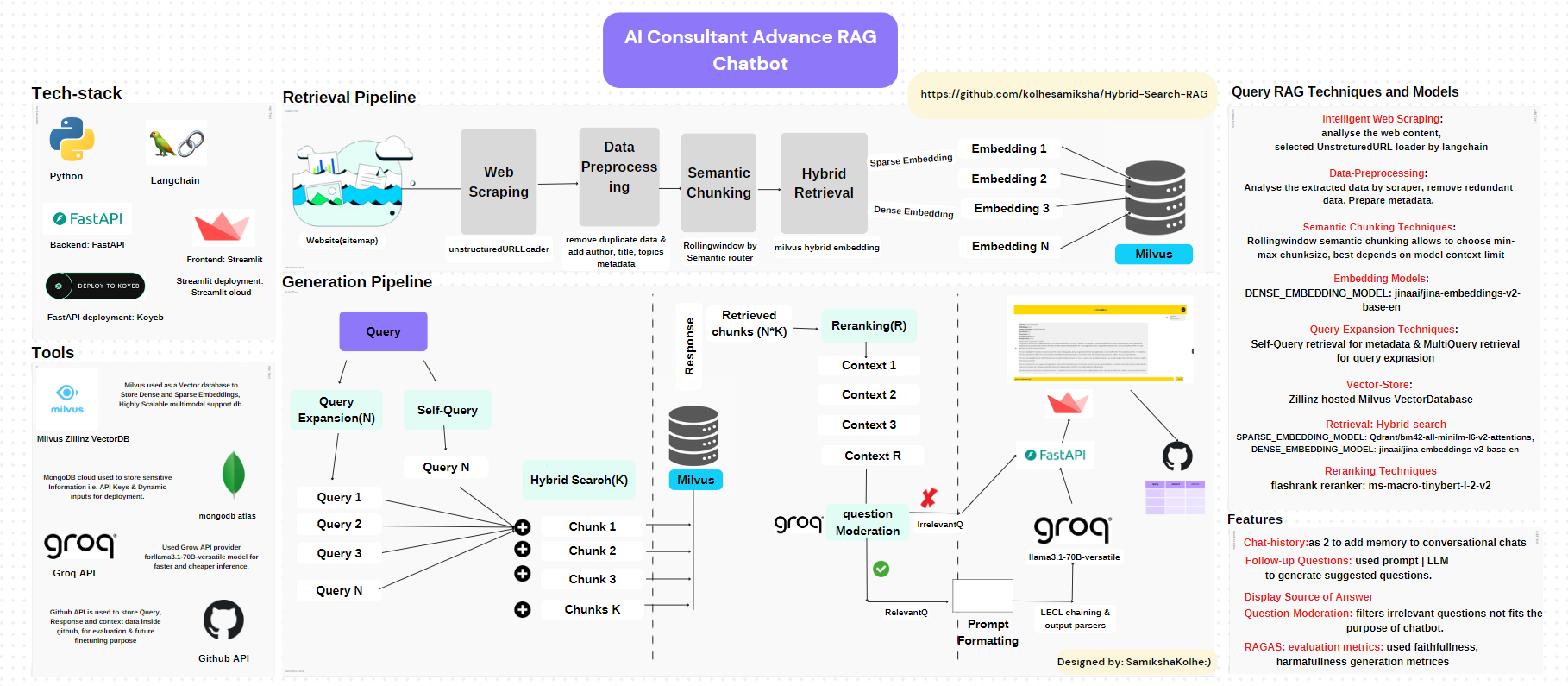
Note: You can Experiment with the Code directly on https://github.com/kolhesamiksha/Hybrid-Search-RAG, Where I’ve in-detail mentioned the steps to Run your code directly without any modification For your own data, Just Follow the repo guidelines to run the Code step by step!! All the Best
You can see in the above Architecture of Use-case, I’ve used Hybrid-Search Approach. Hybrid search is considered to be an advanced RAG Technique. As it’s an advanced RAG technique, there will be some tradeoff between Cost & Latency always in comparison to Simple RAG. Let’s discuss every technique in detail further!!
1. Intelligent Web Scraping:
The Website was a rich source of documents in every domain like AI, Supply chain, Digital, Cybersecurity, and Various Informational Blogs and cases discussed. Most of the websites have a common web interface and HTML Codebase which was suitable to built automation using For Webscraping.
Used Sitemap of Topics under ey_in domain.
Analyze the Structure of the Websites.
Extracted metadata required further for metadata filtering or Self-Query Retriever to post-retrieval for better performance i.e. Author name, related topics, pdf_links. Pdf links were added because most of the blogs contain PDFs for detailed information. in the future content can be extracted and used for training the chatbot for more information.
Built an Automation to scrape and extract 2k websites using unstructuredURLLoader by langchain.
2. Semantic Chunking Techniques:
After WeCrawling and Scraping data from the BaseURL. Applied various Techniques like RecursiveCharacterTextSplitter, Semantic Chunking, Statistical Chunking, and Rolling Window Splitting using Semantic-routing.
RecursiveCharacterTextSplitter: It splits the data by intelligently analysing the structure of the data based on splitting criterias. But Limitation is Not Calculate the semantic similarity between the context while splitting. Hence, Not better if we are unknown to the fact of Structure of Data.
Semantic Chunking: Semantic Chunking splits the data in between the sentences. Based in the similarity between the sentences it combines the sentences and split the data where similarity drops to an extend. It works on embedding Similarity between the Sentences.
2.1 Statistical Chunking: Better for English Text only. Instead of chunking text with a fixed chunk size, the semantic splitter adaptively picks the breakpoint in-between sentences using embedding similarity. This ensures that a "chunk" contains sentences that are semantically related to each other. For Semantic chunking used jinaai/jina-embeddings-v2-base-en (8K context length) by langchain FastEmbedding Module.
2.2 Rolling Window Spltting(Used in RAG): It uses a rolling window to consider splitting and applies semantic similarity while considering the sentence to combine and split. This Technique is more generic for any type of embeddding model, MAX_SPLI, MIN_SPLIT parameters makes it more customisable. Providing Chunks compatible to semantic chunking technique.
3. Metadata Chunking Method:
- Metadata Filtering is a way to limit the searches and increase chances of Information exact retrieval of chunks. For Metadata added Primary_Source_links, author_names, related_topics, and pdf_links metadata fields inside the chunks.
4: Embedding Models:
Tried Different types of embedding models by considering system Size and Best performance for english text on MTEB. Used Fastembedding() from langchain to get the embeddings best models available for local instead of API. Local Embedding Hosting saves the credits and Manage the latency during retrieval pipeline.
Used Embedding model(Hybrid-search): SPARSE_EMBEDDING_MODEL: Qdrant/bm42-all-minilm-l6-v2-attentions, DENSE_EMBEDDING_MODEL: jinaai/jina-embeddings-v2-base-en.
5. Vector-Store: Zillinz hosted Milvus Store:
- Used Milvus to store the embeddings, pymilvus module is more customizable for hybrid search and more scalable with Task-Specific embedding indexes available for dense and sparse embeddings.
6. Query-Expansion Techniques: Self-Query retrieval for metadata & MultiQuery:
- Query Compression techniques are like Query breakdown, Query expansion (Multiple Queries). Created a Customised MultiQuery Retrieval Class find on Chatbot-streamlit/src/utils/custom_utils.py. Defined my own prompt for Query formulations and breakdown.
7. Metadata-Filtering techniques:
- For Metadata Filtering Used Self-Query Retrieval which used the LLM model to get the filters and structured query relevant to the Query by the User.
8. Retrieval: Hybrid-search:
- Used Hybrid Search By milvus, Stored Sparse and Dense vectors indexes inside the milvus collection. During retrieval used ANNSSearch to retrieve the Chunks. Applied Hybrid Search on Multiple queries generated by Query-expansion techniques + Metadata-filtering by Self-Query Over Sparse & Dense embedding search Limit 3 Each. Total for 5 queries using Sparse search generated: 15 chunks & using Dense search generated: 15 chunks Subtotal 30 Chunks Retrieved.
9. Reranking Techniques:
The reranking technique is Important and Useful When applied Self-query & Multi query generation technique to Re-rank the Chunks and Retrieve most Ranked with High similarity To consider and send as Context to LLM.
Re-ranking Models: Used Flashrank default Local Reranking model:ms-macro-tinybert-l-2-v2. SPLADE/Colbert are most used reranking models and perform best.
10. LLM Model:
- LLM Model: Used llama3.1-70B-versatile model API from Groq Fast Inference Provider.
Extra Features Added on top of the Generation phase are discussed below:
Chat-History: Chat-history adds memory to the conversation, Used chat-history as 2 reason being context-window limitation.
Follow-up Questions: Added 5 follow-up questions which helps users to ask relevant next question to the current question, improves conversation flow..
Sources in the response: displaying sources of the data from which the real answer is getting picked up and generated. Useful for this usecase as it contains multiple websites comes under same domain/context.
Question Moderation: Question Moderation is used to not sent the irrelevant question to the LLM.
RAGAS Evaluation Metrices: faithfulness, context_utilization, harmfulness, correctness.
Backend Developement Used FastAPI & For Frontend used Streamlit application. For
FastAPI deployement used Koyeb platform, provides scalable infrastructure to deploy FastAPI applications and Provides API.
For Streamlit Application deployment used Streamlit cloud.
Feature: Experts says while building RAG systems, always create an Evaluation dataset while experimenting or during POC, which helps further for RAG performance improvement and Finetuning as well. Hence saving the Question, Answer and retrieved documents inside Github using Github API.
Observation and Difficulties Faced During Performance Improvement of the Chatbot
Hallucination: Model hallucination is reduced by tweaking model parameters, refining the prompt and based on user feedback refined the prompt.
Latency: Latency depends upon two things: 1. Architecture complexity 2. API calls & Resources/Infrastructure used for deployment. For this chatbot requires average 2 minutes to display the answer.
Cost: Cost can be reduced upto some mark by compressing the prompt, used llm-lingua, which reduces 20% of the prompt with no degrade in performance.
The problems I Faced during the stages of the RAG and what relevant solutions applied based on the Problems are pointed out in next section.
RAG System Challenges & Practical Solutions:
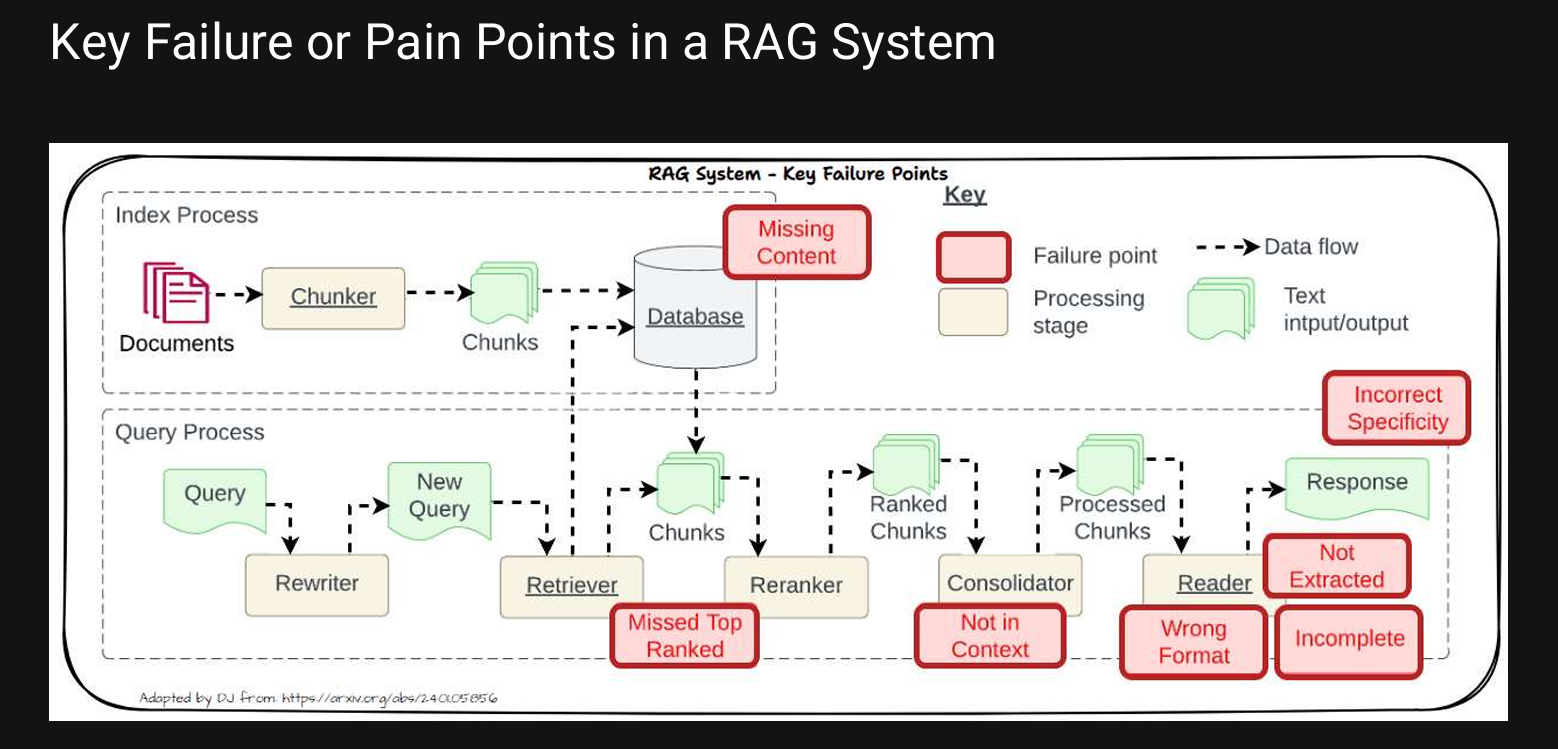
Let’s discuss the Problems and their solutions one by one here!!
Note: The problems mentioned in the above diagram are in detail discussed below, please refer the above image while reading the content below!!
Problem1:
Missing Content
Missing Content means the relevant context to answer the question is not present in the database.
Leads to the model giving a wrong answer and hallucinating.
End users end up being frustrated with irrelevant or wrong responses,
Solution: Missing Content
Better data cleaning using tools like unstructured.io to ensure we extract good quality data.
Better prompting to constrain the model to NOT answer the question if the context is irrelevant.
Agentic RAG with search tools to get live information for question with no context data.
Problem2:
Missed Top Ranked
Missed Top Ranked means context documents don’t appear in the top retrieval results.
Leads to the model not able to answer the question
Documents to answer the question are present but failed to get retrieved due to poor retrieval strategy.
Problem3:
Not in Context
Not in Context means documents with the answer are present during initial retrieval but did not make it into the final context for generating an answer.
Bad retrieval, reranking and consolidation strategies lead to missing out on the right documents in context.
Problem4:
Not Extracted
Not extracted means the LLM struggles to extract the correct answer from the provided context even if it has the answer.
This occurs when there is too much unnecessary information, noise or contradicting information in the context.
Problem5:
Incorrect Specificity
Output response is too vague and is not detailed or specific enough.
Vague or generic queries might lead to not getting the right context and response.
Wrong chunking or bad retrieval can lead to this problem.
Solution for Problems 2 to 5:
Use Better Chunking Strategies
Hyperparameter Tuning - Chunking & Retrieval
Use Better Embedder Models
Use Advanced Retrieval Strategies
Use Context Compression Strategies
Use Better Reranker Models.
Problem6:
Wrong Format
The output response is in the wrong format.
It happens when you tell the LLM to return the response in a specific format e.g. JSON and it fails to do so.
Solution for Wrong Format:
Powerful LLMs have native support for response formats e.g. OpenAI supports JSON outputs.
Better Prompting and Output Parsers.
Structured Output Frameworks.
Problem7:
Incomplete
Incomplete means the generated response is incomplete.
This could be because of poorly worded questions, lack of right context retrieved, bad reasoning.
Solutions for Incomplete Answer
Use Better LLMs like GPT-4o, Claude 3.5 or Gemini 1.5.
Build Agentic Systems with Tool Use if necessary.
Use Advanced Prompting Techniques like Chain-of-Thought, Self-Consistency.
Rewrite User Query and Improve Retrieval - HyDE.
RAG V/s Long Context LLM
Let’s see why RAG will continue to be the first choice for many production-grade applications today!! Pros and Cons of Using RAG over Long context LLM’s.

The Case for Long Context LLMs
There are some challenges that long-context LLMs can solve today:
On-the-fly retrieval and reasoning
Long context enables ongoing retrieval and reasoning at every stage of the decoding process, in contrast to RAG, which conducts retrieval only initially and then applies it to subsequent tasks.
By putting all the data into a long context, the LLM can more easily understand the subtle relationships between pieces of information.
Reduced Complexity
One big benefit from long-context is that developers won’t pull their hair out over what combination of chunking strategy, embedding model, and retrieval method they’ll need to use.
Developers can consolidate much more or even all of their data into a single, lengthy prompt and rely on the (reported!) nearly perfect recall capabilities of LLMs to obtain accurate answers.
Reduced Latency
Simplifying AI workflows leads to fewer prompt chains and less delay. But it's unclear how much this will help right now, because long context prompts can still cause a big spike in latency.
We anticipate that new methods will make longer context prompts faster and cheaper, leading us to the next section.
Long context can be faster, and cheaper with better caching
Large language models use the KV (Key-Value) cache as its memory system to store and quickly access important information during inference. This means that you can read the input once, and then all subsequent queries will reuse the stored KV cache.
With KV cache we trade memory against consumption, which imposes another challenge that can be very costly.
However, researchers are starting to test new compression cache algorithms to serve models such as LLaMa 7B with 10 million tokens, on an 8-GPU serving system. We'll see a lot more innovation in this area, which will make long context queries much faster and more cost-effective.
Another area is building new processors designed specifically for LLM applications such as the LPU Inference Engine by Groq.
The Case for RAG (Retrieval Augmented Generation)
Developers are continuously building advanced RAG architectures, and this approach continues to be the number one choice for many of them because:
RAG is Faster and Cheaper
Attempting to process a 1 million token window today, will result in slow end-to-end processing times and a high cost.
In contrast, RAG is the fastest and cheapest option to augment LLM models with more context. Beyond naive RAG, developers and researchers have built many complex RAG architectures that optimize every step of their systems making it a very reliable architecture for their use-cases.
Easier to debug and evaluate
If too much context is provided, it's challenging to debug and evaluate whether a hallucination happened based on context or unsupported content.
Using less context per prompt offers a benefit in terms of explainability, because developers can understand what the LLM relied on to formulate its response.
Even with the maximum input size today (200K) model providers recommend splitting prompts and chaining them together for handling complex reasoning tasks, and we don’t see this changing in the near future.
Up-to-date information
When developers use RAG, it’s pretty easy to serve the model with up-to-date information from wherever they store company data. Leveraging tools like vector databases or external calls allows the LLM to generate informed outputs, making it essential for numerous current use cases.
Can solve for Lost in the Middle (LIM)
Recent research indicates that performance peaks when key information is at the start or end of the input context, but drops if relevant details are mid-context. So to achieve best performance, developers should strategically place the most relevant documents at the start and end of the prompt, a task that can be very manual/complex if done with the long context approach.
RAG can simplify this process; they can select any retriever, fetch the top N similar documents, then employ a custom reranking function to reorder the results, positioning the least relevant documents in the middle.
Deterministic security/access privilege
Apart from building the best architecture, developers are thinking of building safe and reliable AI apps. By employing deterministic mechanisms in the chain, RAG allows for precise control over who can access what information, ensuring confidentiality and integrity of sensitive data.
This is one of the most important reasons why RAG will continue to be the first choice for many production-grade applications.
But, Nowadays More Hybrid Approaches of RAG & Long-Context LLMs are being developed, Most of them are based on an Agentic RAG System. The Categorie of New approaches using Agents are self-router RAG, Agentic corrective RAG, and Agentic self-reflection RAG are described below:
I’ll not go in detail on all 3 approaches, from their the diagram the system can be analysed and the approach can be studied. s
Hybrid Approach 1: Self-Router RAG
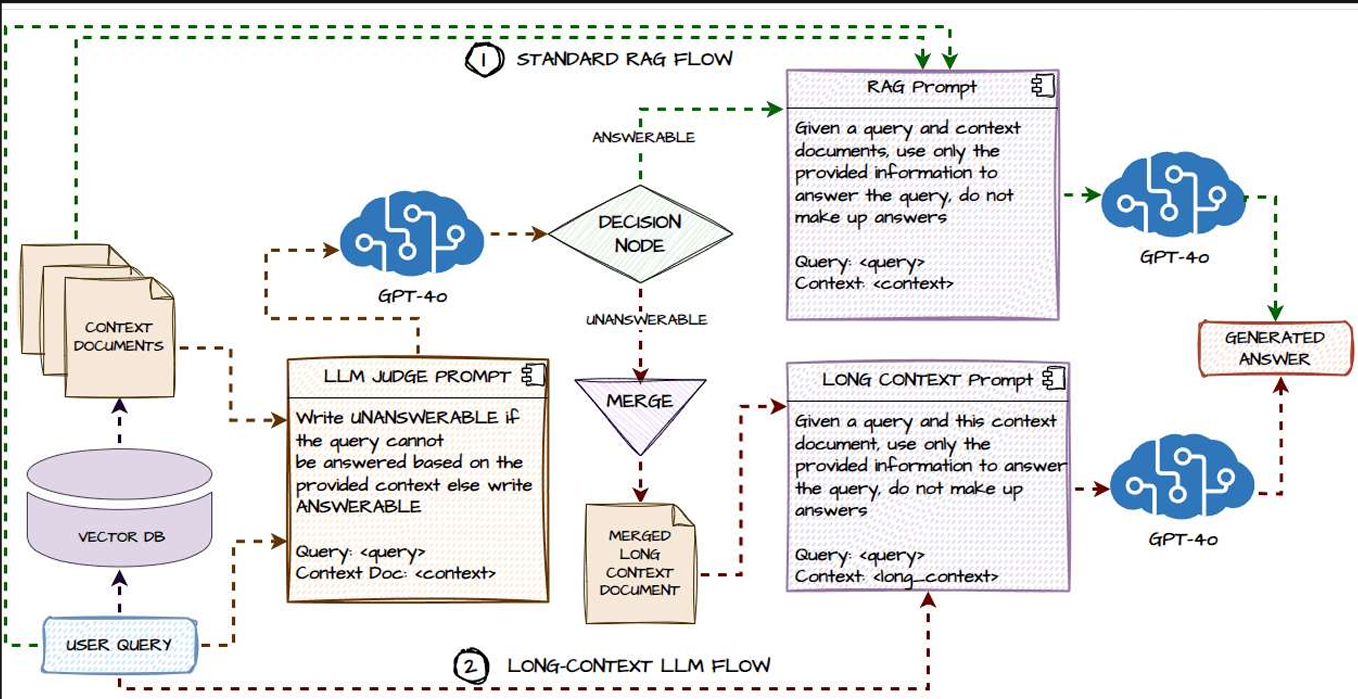
Hybrid Approach 2: Agentic Corrective RAG
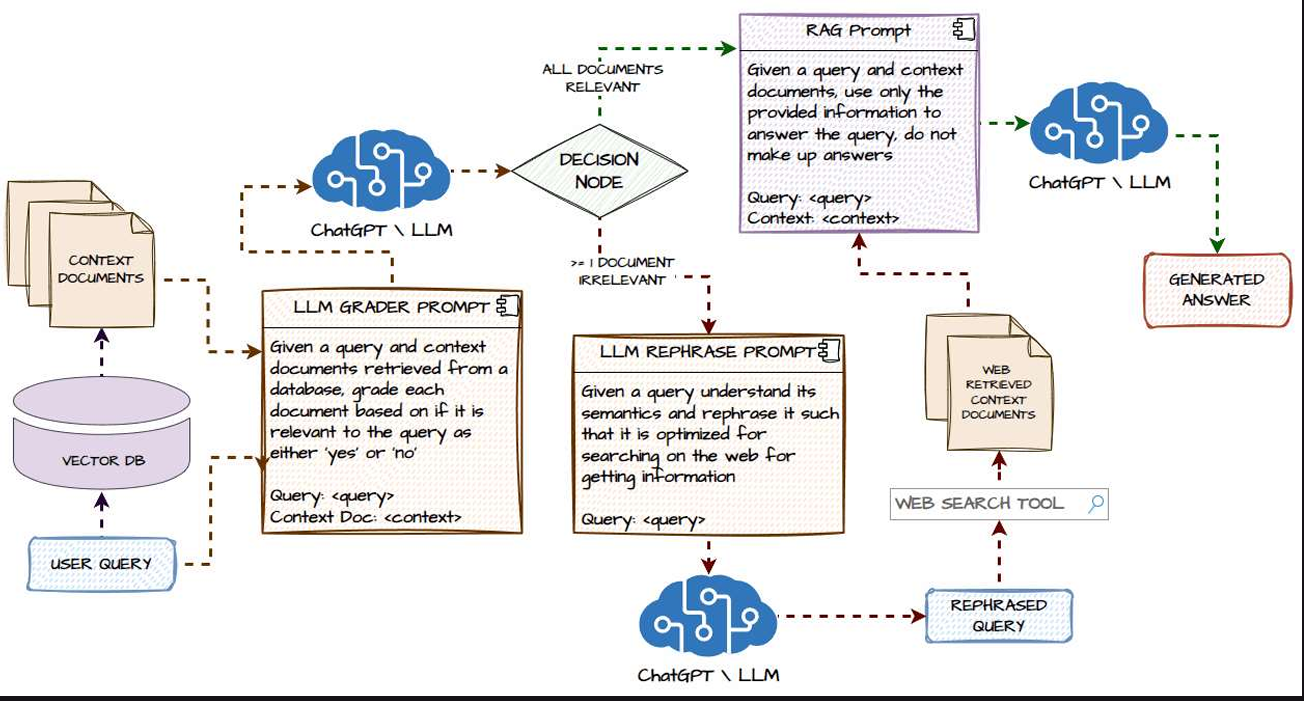
Hybrid Approach 3: Agentic Self-Reflection RAG
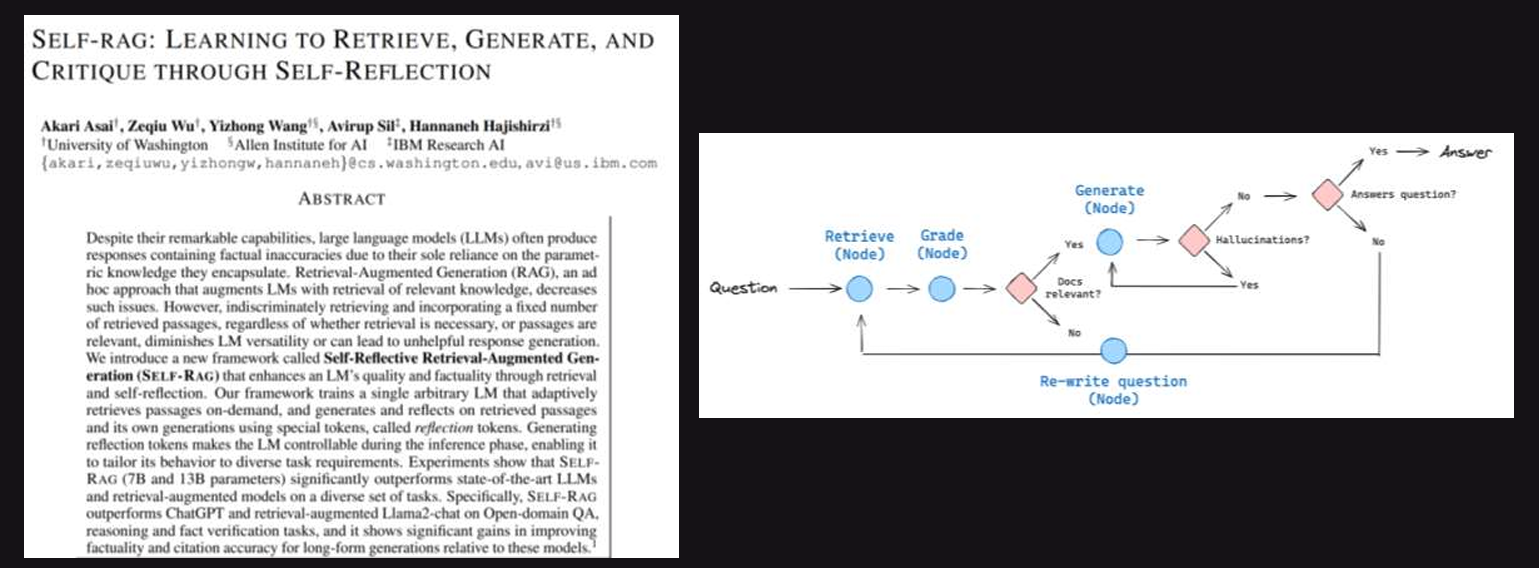
Popular Production Ready RAG Architectures by NVIDIA
Key Takeaways from Industry Experts on Building RAG Systems✨
RAG is still very much a retrieval problem.
Explore various chunking and retrieval strategies, don’t stick to default settings
Agentic RAG systems and domain-specific fine-tuned RAG systems are the future
Build an evaluation dataset and always evaluate your RAG system.
Even with Long Context LLMs, RAG isn’t going anywhere (for now).
BONUS: Retrieval Augmented Fine-tuning (RAFT)
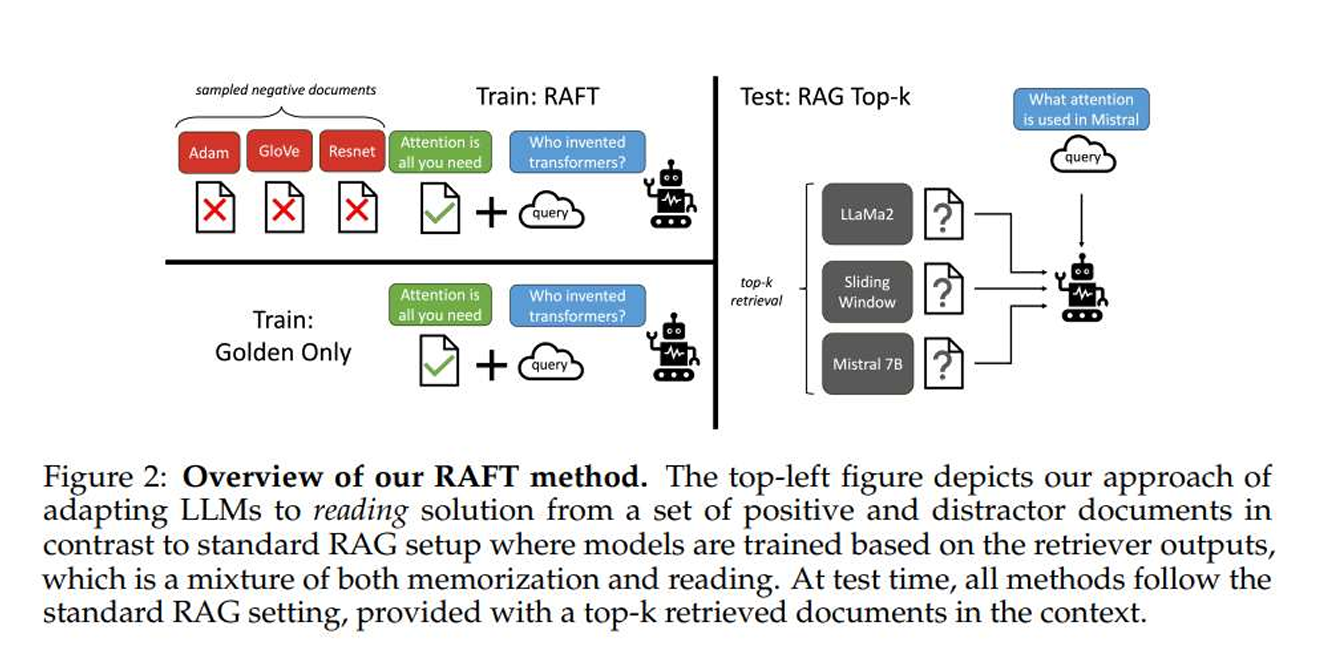
RAFT combines RAG and fine-tuning and provides a training recipe that improves the model's ability to answer questions in an 'open-book' domain setting
In conventional RAG, when a query is posed to a model, it retrieves a few documents from an index that are likely to contain the answer. It uses these documents as the context to generate an answer to the user’s query.
A recent research paper from UC Berkeley explores how to mix supervised fine-tuning (SFT) with retrieval augmented generation (RAG) with a new approach called retrieval augmented fine-tuning (RAFT).
RAFT is about teaching LLMs to get smarter about specific topics while improving in-domain RAG performance. RAFT not only ensures the models are well-trained on domain-specific knowledge through fine-tuning but also ensures they're robust against inaccurate retrievals. This is done by training models to understand how the question, the documents found, and the correct answer fit together. It's like studying for an open-book test by learning to spot what's important in your notes and what's not.
With retrieval augmented fine-tuning, we train the model to take a question and documents (even the distracting ones) and come up with an answer that follows a logical thought process. RAFT has proven to be better than just supervised fine-tuning, whether RAG is used or not, across different datasets like PubMed, HotpotQA, and others from HuggingFace Hub, Torch Hub, and TensorFlow Hub Gorilla, showing a simple yet effective way to boost LLMs for specific topics.
How does RAFT work?
RAFT is a new way of “domain-specific open-book exam”. Let’s first start from supervised fine-tuning (SFT), then explore RAFT in more detail.
Supervised fine-tuning (SFT)
In SFT, we use a dataset of questions and answers. The idea is to train the model to get better at giving the right answers using what it already knows from earlier training or what it learns while being fine-tuned. Once trained, this model can also be used with additional documents to help it find answers (RAG). Here’s a simple way to see how it works:
Training: The model learns to go from a question to an answer (Q → A).
Testing without extra info (0-shot Inference): It uses what it learned to answer new questions (Q → A).
Testing with RAG (RAG Inference): It gets extra documents to help answer questions (Q+D → A).
RAFT
- Retrieval aware fine-tuning (RAFT) offers a new way to set up training data for models, especially for domain-specific open-book scenarios similar to in-domain RAG. In RAFT, we create training data that includes a question (Q), some documents (Dk), and a corresponding chain-of-thought (CoT) answer (A*) that’s based on information from one of the documents (D*). We distinguish between two types of documents: the 'oracle' documents (D*) that have the information needed for the answer, and 'distractor' documents (Di) that don’t help with the answer. Some of the training involves having the right document along with distractions, while other times, we only include distractor documents to encourage the model to rely on its memory rather than just the documents provided.

This process looks like this:
- For some data, we have a question plus the right document and distractions leading to the answer (Q+D*+D2+...+Dk → A*).
- For other data, we only have a question and distractions, which still lead to an answer (Q+D1+D2+...+Dk → A*).
When testing, the model gets a question and the top documents found by the RAG setup, but RAFT works no matter which tool is used to find these documents.
A crucial part of the training involves teaching the model to build a chain of reasoning to explain its answers, much like writing out your steps in math homework. This approach involves giving the model all the context and information it needs, then asking it to explain its answer step by step, linking back to the original documents. For all the datasets that are mentioned in the paper, the researchers used this method to create answers that include reasoning. Some datasets, like the Gorilla APIBench, already include reasoned answers. We show that adding these detailed explanations helps the model perform better, proven by our experiments.

above is a RAFT prompt to help LLM evaluate its own generated reasoning and answers, contrasting them with the correct reasoning and answers.
Results
- Using the selected datasets and comparison models, the RAFT model results are shown below. RAFT consistently performs better than the other models compared to it. For example, when compared to the Llama-2 model that's been tuned for instructions, RAFT, especially when combined with RAG, is much more effective at pulling information from documents and ignoring irrelevant ones. The improvement can be as high as 35.25% on Hotpot QA and 76.35% on Torch Hub.

When comparing retrieval augmented fine-tuning to domain-specific fine-tuning (DSF) on certain datasets, RAFT is better at using the given context to answer questions. It shows significant improvements on the HotpotQA and HuggingFace datasets, with increases of 30.87% and 31.41% respectively. However, for PubMed QA, which is based on yes/no questions, RAFT doesn't show as big an improvement over DSF + RAG.
Even when put against a much larger model like GPT-3.5, RAFT shows clear advantages. Generally, the LLaMA-7B model, with or without RAG, didn't do as well because its way of answering questions didn't match what was needed. By applying specific tuning for the domain, RAFT showed better performance. This tuning helps the model learn the right way to answer questions. However, just adding RAG to a model that's been fine-tuned for a specific domain doesn't always lead to better results, suggesting that the model may need more training on how to use context effectively and extract useful information from it. By using RAFT, we train the model not only to align its answers better but also to enhance its ability to process documents. As a result, this approach outperforms the others.
Andd!!! Here’s come to the end🥳, In this article we’ve discussed a lot about the Retrieval Augmented Generation Systems, learned from very basics of introduction to RAG → How RAG works → RAG system and architectures → Building a Full-stack RAG App → Understanding practical RAG failures and solutions → More Advance RAG architectures (Agentic RAG systems) → Key-takeaways by experts on RAG → RAFT(Retrieval + Finetuning).
In the next Article I’ll discuss about Agentic RAG & Multimodal RAG systems through Practical Examples!!!
Please feel free to contribute to this article in comments, share your insights and experience in building and improving RAG systems. This will help everyone to learn from each others experience!!!.
till then, Stay tuned and follow our newsletter to get daily updates & Built Project End to end!! Connect with me on linkedin, github, kaggle.
Let's Learn and grow together:) Stay Healthy stay Happy✨. Happy Learning!!




