

Every Developer Should Know: Advance Prompt Engineering Techniques

Hey I'm Samiksha Kolhe. a Data Enthusiast and aspiring Data Scientist. One day Fascinated by a fact that "We can built Time machines and predict future using AI". That hit my dream to explore the Vector space and find out what the dark matter is about. World and Technology every day brings new challenges, and new learnings. Technology fascinated me, I'm constantly seeking out new challenges and opportunities to learn and grow. A born-ready girl with deep expertise in ML, Data Science, and Deep Learning, generative AI. Curious & Self-learner with a go-getter attitude that pushes me to build things. My passion lies in solving business problems with the help of Data. Love to solve customer-centric problems. Retail, fintech, e-commerce businesses to solve the customer problems using Data/AI. Currently learning MLops to build robust Data/ML systems for production-ready applications. exploring GenAI. As a strong collaborator and communicator, I believe in the power of teamwork and diversity of thoughts to solve a problem. I'm always willing to lend a helping hand to my colleagues and juniors. Through my Hashnode blog, I share my insights, experiences, and ideas with the world. I love to writing about latest trends in AI and help students/freshers to start in their AI journey. Outside technology I'm a spiritual & Yoga person. Help arrange Yoga and mediation campaigns, Volunteering to contribute for better society. Love Travelling, Reading and Learn from world.
Hello Techies👋! Hope you all are doing amazing stuff. I'm back with another amazing and trending stuff in market today i.e. Prompt Engineering. It's sort of techniques to use openAI or opensource LLM's to use efficiently with 100% of their potential.
You as a Developer can make use of these techniques to get most out of the best from ChatGPT:).
Note: If you wanted to know how to use OpenAI API's to create and built your conversational applications with using below prompt-engineering techniques. Stay-tuned and subscribe to newsletter to receive articles regarding GenAI.
Excited!! Let's see Our Agenda first. The prompt engineering techniques discussed further as follow:
Zero shot prompting.
few shot prompting.
chain-of-thought prompting.
Automatic chain-of-thought (Cot) Prompting.
Self-consistency.
Prompt chaining.
Tree of Thought prompting.
Retrieval Augmented Generation (RAG).
Active Prompt.
Multi-modal CoT.
Let's get Started!!
Zero-Shot Prompting:
Large LLMs today, such as GPT-3, are tuned to follow instructions and are trained on large amounts of data; so they are capable of performing some tasks "zero-shot."
We tried a few zero-shot examples in the previous section. Here is one of the examples we used:
Prompt:
Classify the text into neutral, negative or positive. Text: I think the vacation is okay. Sentiment:
Output:
Neutral
Note that in the prompt above we didn't provide the model with any examples of text alongside their classifications, the LLM already understands "sentiment" -- that's the zero-shot capabilities at work.
Instruction tuning has shown to improve zero-shot learning. Instruction tuning is essentially the concept of finetuning models on datasets described via instructions. Furthermore, RLHF (reinforcement learning from human feedback) has been adopted to scale instruction tuning wherein the model is aligned to better fit human preferences. This recent development powers models like ChatGPT. We will discuss all these approaches and methods in upcoming sections.
When zero-shot doesn't work, it's recommended to provide demonstrations or examples in the prompt which leads to few-shot prompting. In the next section, we demonstrate few-shot prompting.
Few-Shot Prompting:
While large-language models demonstrate remarkable zero-shot capabilities, they still fall short on more complex tasks when using the zero-shot setting. Few-shot prompting can be used as a technique to enable in-context learning where we provide demonstrations in the prompt to steer the model to better performance. The demonstrations serve as conditioning for subsequent examples where we would like the model to generate a response.
Let's demonstrate few-shot prompting via an example. In the example, the task is to correctly use a new word in a sentence.
Prompt:
A "whatpu" is a small, furry animal native to Tanzania. An example of a sentence that uses the word whatpu is:We were traveling in Africa and we saw these very cute whatpus. To do a "farduddle" means to jump up and down really fast. An example of a sentence that uses the word farduddle is:
Output:
When we won the game, we all started to farduddle in celebration.
We can observe that the model has somehow learned how to perform the task by providing it with just one example (i.e., 1-shot). For more difficult tasks, we can experiment with increasing the demonstrations (e.g., 3-shot, 5-shot, 10-shot, etc.).
Here are a few more tips about demonstrations/exemplars when doing few-shot:
"the label space and the distribution of the input text specified by the demonstrations are both important (regardless of whether the labels are correct for individual inputs)"
the format you use also plays a key role in performance, even if you just use random labels, this is much better than no labels at all.
additional results show that selecting random labels from a true distribution of labels (instead of a uniform distribution) also helps.
Let's try out a few examples. Let's first try an example with random labels (meaning the labels Negative and Positive are randomly assigned to the inputs):
Prompt:
This is awesome! // NegativeThis is bad! // PositiveWow that movie was rad! // PositiveWhat a horrible show! //
Output:
Negative
We still get the correct answer, even though the labels have been randomized.
Note that we also kept the format, which helps too. In fact, with further experimentation, it seems the newer GPT models we are experimenting with are becoming more robust to even random formats. Example:
Prompt:
Positive This is awesome! This is bad! NegativeWow that movie was rad!PositiveWhat a horrible show! --
Output:
Negative
There is no consistency in the format above but the model still predicted the correct label. We have to conduct a more thorough analysis to confirm if this holds for different and more complex tasks, including different variations of prompts.
Standard few-shot prompting works well for many tasks but is still not a perfect technique, especially when dealing with more complex reasoning tasks. Let's demonstrate why this is the case. Do you recall the previous example where we provided the following task:
Prompt
The odd numbers in this group add up to an even number: 15, 32, 5, 13, 82, 7, 1. A:
If we try this again, the model outputs the following:
Yes, the odd numbers in this group add up to 107, which is an even number.
This is not the correct response, which not only highlights the limitations of these systems but that there is a need for more advanced prompt engineering.
Limitations of Few-Shot learning are mentioned below.
Let's try to add some examples to see if few-shot prompting improves the results.
Prompt
The odd numbers in this group add up to an even number: 4, 8, 9, 15, 12, 2, 1.A: The answer is False.The odd numbers in this group add up to an even number: 17, 10, 19, 4, 8, 12, 24.A: The answer is True.The odd numbers in this group add up to an even number: 16, 11, 14, 4, 8, 13, 24.A: The answer is True.The odd numbers in this group add up to an even number: 17, 9, 10, 12, 13, 4, 2.A: The answer is False.The odd numbers in this group add up to an even number: 15, 32, 5, 13, 82, 7, 1. A:
Output:
The answer is True.
That didn't work. It seems like few-shot prompting is not enough to get reliable responses for this type of reasoning problem. The example above provides basic information on the task. If you take a closer look, the type of task we have introduced involves a few more reasoning steps. In other words, it might help if we break the problem down into steps and demonstrate that to the model. More recently, chain-of-thought (CoT) prompting. has been popularized to address more complex arithmetic, commonsense, and symbolic reasoning tasks.
Overall, it seems that providing examples is useful for solving some tasks. When zero-shot prompting and few-shot prompting are not sufficient, it might mean that whatever was learned by the model isn't enough to do well at the task. From here it is recommended to start thinking about fine-tuning your models or experimenting with more advanced prompting techniques. Up next we talk about one of the popular prompting techniques called chain-of-thought prompting which has gained a lot of popularity.
Chain-of-Thought Prompting:
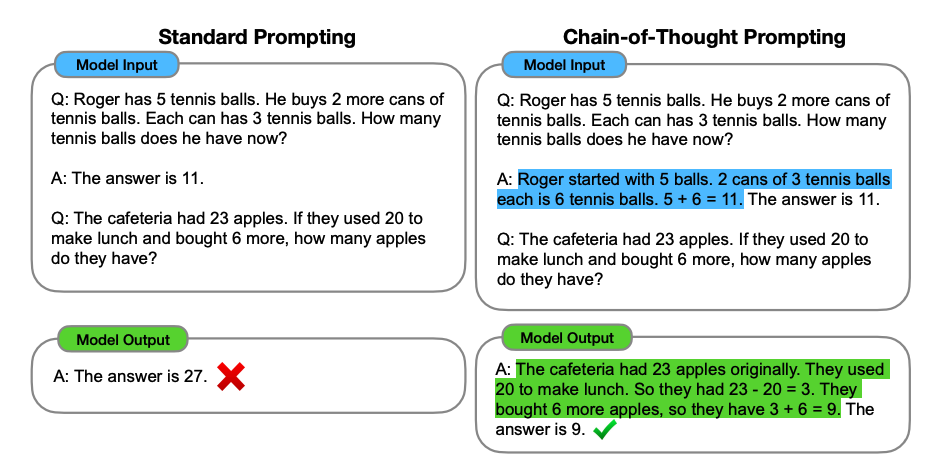
Chain-of-thought (CoT) prompting enables complex reasoning capabilities through intermediate reasoning steps. You can combine it with few-shot prompting to get better results on more complex tasks that require reasoning before responding.
Prompt:
The odd numbers in this group add up to an even number: 4, 8, 9, 15, 12, 2, 1.A: Adding all the odd numbers (9, 15, 1) gives 25. The answer is False.The odd numbers in this group add up to an even number: 17, 10, 19, 4, 8, 12, 24.A: Adding all the odd numbers (17, 19) gives 36. The answer is True.The odd numbers in this group add up to an even number: 16, 11, 14, 4, 8, 13, 24.A: Adding all the odd numbers (11, 13) gives 24. The answer is True.The odd numbers in this group add up to an even number: 17, 9, 10, 12, 13, 4, 2.A: Adding all the odd numbers (17, 9, 13) gives 39. The answer is False.The odd numbers in this group add up to an even number: 15, 32, 5, 13, 82, 7, 1. A:
Output:
Adding all the odd numbers (15, 5, 13, 7, 1) gives 41. The answer is False.
Wow! We can see a perfect result when we provided the reasoning step. In fact, we can solve this task by providing even fewer examples, i.e., just one example seems enough:
Prompt:
The odd numbers in this group add up to an even number: 4, 8, 9, 15, 12, 2, 1.A: Adding all the odd numbers (9, 15, 1) gives 25. The answer is False.The odd numbers in this group add up to an even number: 15, 32, 5, 13, 82, 7, 1. A:
Output:
Adding all the odd numbers (15, 5, 13, 7, 1) gives 41. The answer is False.
Zero-shot COT Prompting:

One recent idea that came out more recently is the idea that essentially involves adding "Let's think step by step" to the original prompt. Let's try a simple problem and see how the model performs:
Prompt:
I went to the market and bought 10 apples. I gave 2 apples to the neighbor and 2 to the repairman. I then went and bought 5 more apples and ate 1. How many apples did I remain with?
Output:
11 apples
The answer is incorrect! Now Let's try with the special prompt.
Prompt:
I went to the market and bought 10 apples. I gave 2 apples to the neighbor and 2 to the repairman. I then went and bought 5 more apples and ate 1. How many apples did I remain with?Let's think step by step.
Output:
First, you started with 10 apples.You gave away 2 apples to the neighbor and 2 to the repairman, so you had 6 apples left.Then you bought 5 more apples, so now you had 11 apples.Finally, you ate 1 apple, so you would remain with 10 apples.
It's impressive that this simple prompt is effective at this task. This is particularly useful where you don't have too many examples to use in the prompt.
This technique help me a lot. I most of the times or always add this prompt when working on any collective, logical and code generation tasks.
Automatic Chain-of-Thought (Auto-CoT):
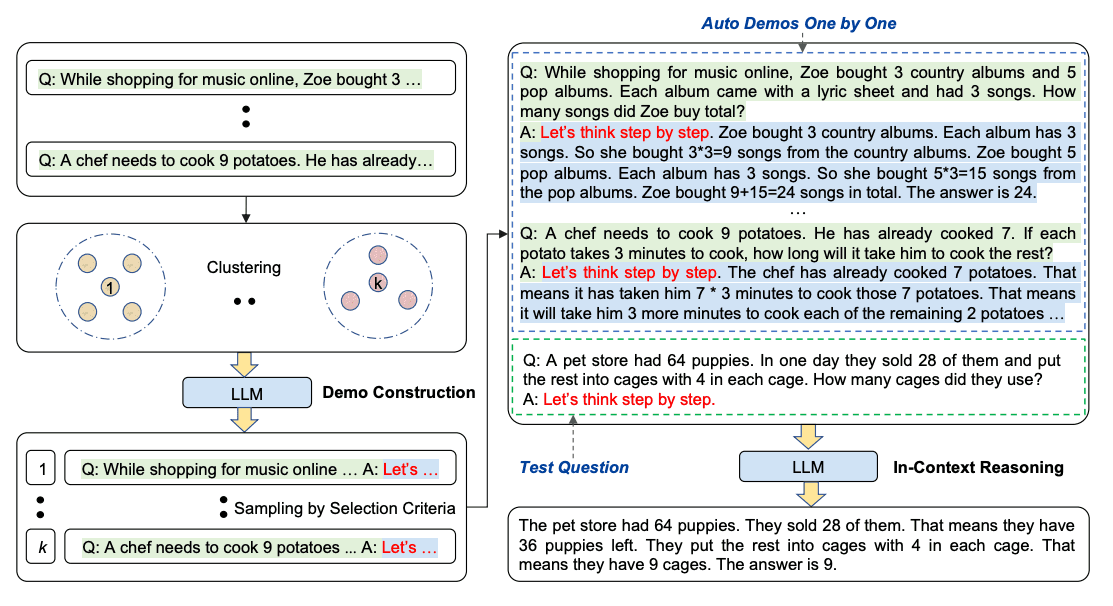
When applying chain-of-thought prompting with demonstrations, the process involves hand-crafting effective and diverse examples. This manual effort could lead to suboptimal solutions. by eliminating manual efforts by leveraging LLMs with "Let's think step by step" prompt to generate reasoning chains for demonstrations one by one. This automatic process can still end up with mistakes in generated chains. To mitigate the effects of the mistakes, the diversity of demonstrations matter. This work proposes Auto-CoT, which samples questions with diversity and generates reasoning chains to construct the demonstrations.
Auto-CoT consists of two main stages:
Stage 1): question clustering: partition questions of a given dataset into a few clusters
Stage 2): demonstration sampling: select a representative question from each cluster and generate its reasoning chain using Zero-Shot-CoT with simple heuristics
The simple heuristics could be length of questions (e.g., 60 tokens) and number of steps in rationale (e.g., 5 reasoning steps). This encourages the model to use simple and accurate demonstrations.
The process is illustrated below:
Self-Consistency:
Perhaps one of the more advanced techniques out there for prompt engineering is self-consistency to replace the naive greedy decoding used in chain-of-thought prompting". The idea is to sample multiple, diverse reasoning paths through few-shot CoT, and use the generations to select the most consistent answer. This helps to boost the performance of CoT prompting on tasks involving arithmetic and commonsense reasoning.
Let's try the following example for arithmetic reasoning:
Prompt:
When I was 6 my sister was half my age. NowI’m 70 how old is my sister?
Output:
35
The output is wrong! How may we improve this with self-consistency? Let's try it out.
Prompt:
Q: There are 15 trees in the grove. Grove workers will plant trees in the grove today. After they are done, there will be 21 trees. How many trees did the grove workers plant today?
A: We start with 15 trees. Later we have 21 trees. The difference must be the number of trees they planted. So, they must have planted 21 - 15 = 6 trees. The answer is 6.Q: If there are 3 cars in the parking lot and 2 more cars arrive, how many cars are in the parking lot?
A: There are 3 cars in the parking lot already. 2 more arrive. Now there are 3 + 2 = 5 cars. The answer is 5.Q: Leah had 32 chocolates and her sister had 42. If they ate 35, how many pieces do they have left in total?
A: Leah had 32 chocolates and Leah’s sister had 42. That means there were originally 32 + 42 = 74chocolates. 35 have been eaten. So in total they still have 74 - 35 = 39 chocolates. The answer is 39.Q: Jason had 20 lollipops. He gave Denny some lollipops. Now Jason has 12 lollipops. How many lollipopsdid Jason give to Denny?
A: Jason had 20 lollipops. Since he only has 12 now, he must have given the rest to Denny. The number oflollipops he has given to Denny must have been 20 - 12 = 8 lollipops. The answer is 8.Q: Shawn has five toys. For Christmas, he got two toys each from his mom and dad. How many toys doeshe have now?
A: He has 5 toys. He got 2 from mom, so after that he has 5 + 2 = 7 toys. Then he got 2 more from dad, soin total he has 7 + 2 = 9 toys. The answer is 9.Q: There were nine computers in the server room. Five more computers were installed each day, frommonday to thursday. How many computers are now in the server room?
A: There are 4 days from monday to thursday. 5 computers were added each day. That means in total 4 * 5 =20 computers were added. There were 9 computers in the beginning, so now there are 9 + 20 = 29 computers.The answer is 29.Q: Michael had 58 golf balls. On tuesday, he lost 23 golf balls. On wednesday, he lost 2 more. How manygolf balls did he have at the end of wednesday?
A: Michael initially had 58 balls. He lost 23 on Tuesday, so after that he has 58 - 23 = 35 balls. OnWednesday he lost 2 more so now he has 35 - 2 = 33 balls. The answer is 33.Q: Olivia has $23. She bought five bagels for $3 each. How much money does she have left?
A: She bought 5 bagels for $3 each. This means she spent $15. She has $8 left.Q: When I was 6 my sister was half my age. Now I’m 70 how old is my sister?
A:
Output 1:
When I was 6 my sister was half my age, so she was 3. Now I am 70, so she is 70 - 3 = 67. The answer is 67.
Output 2:
When the narrator was 6, his sister was half his age, which is 3. Now that the narrator is 70, his sister would be 70 - 3 = 67 years old. The answer is 67.
Output 3:
When I was 6 my sister was half my age, so she was 3. Now I am 70, so she is 70/2 = 35. The answer is 35.
Computing for the final answer involves a few steps. but for the sake of simplicity, we can see that there is already a majority answer emerging so that would essentially become the final answer.
Prompt Chaining:
To improve the reliability and performance of LLMs, one of the important prompting engineering techniques is to break tasks into its subtasks. Once those subtasks have been identified, the LLM is prompted with a subtask and then its response is used as input to another prompt. This is what's referred to as prompt chaining where a task is split into subtasks with the idea to create a chain of prompt operations.
Prompt chaining is useful to accomplish complex which an LLM might struggle to address if prompted with a very detailed prompt. In prompt chaining, chain prompts perform transformations or additional processes on the generated responses before reaching a final desired state.
Besides achieving better performance, prompt chaining helps to boost transparency of your LLM application, increases controllability, and reliability. This means that you can debug problems with model responses much easier and analyze and improve performance in the different stages that need improvement.
Prompt chaining is particularly useful when building LLM-powered conversational assistants and improving the personalization and user experience of your applications.
Use Cases for Prompt Chaining
Prompt Chaining for Document QA
Prompt chaining can be used in different scenarios that could involve several operations or transformations. For instance, one common use case of LLMs involves answering questions about a large text document. It helps if you design two different prompts where the first prompt is responsible for extracting relevant quotes to answer a question and a second prompt takes as input the quotes and original document to answer a given question. In other words, you will be creating two different prompts to perform the task of answering a question given a document.
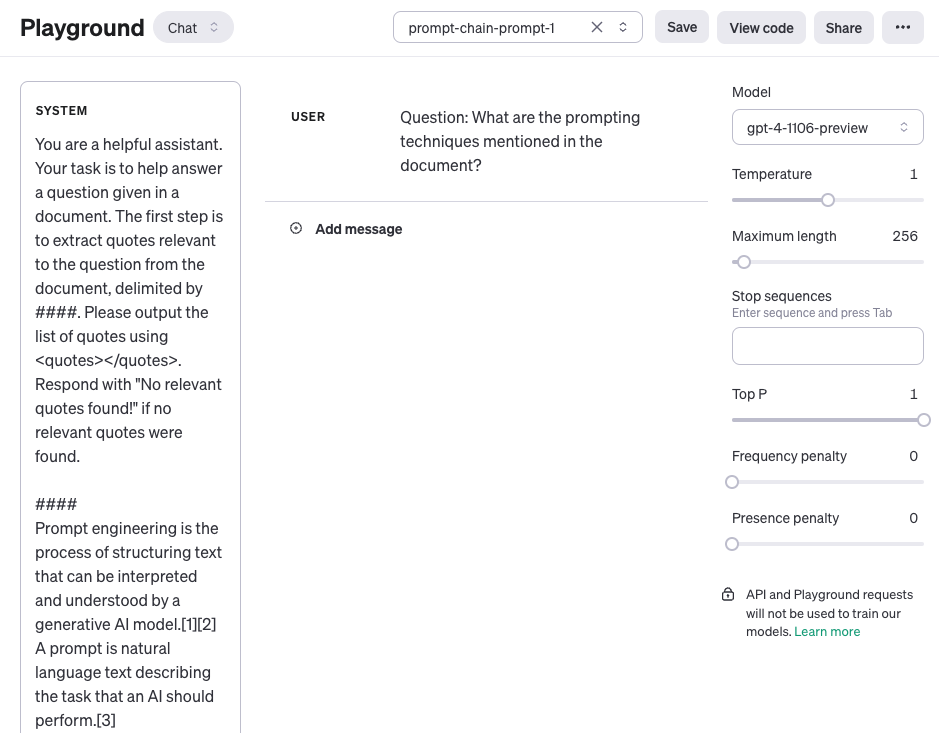
The first prompt below extracts the relevant quotes from the document given the question. Note that for simplicity, we have added a placeholder for the document {{document}}. Due to larger context used for this task, we are using the gpt-4-1106-preview model from OpenAI. You can use the prompt with other long-context LLMs like Claude.
Prompt 1:
You are a helpful assistant. Your task is to help answer a question given a document. The first step is to extract quotes relevant to the question from the document, delimited by ####. Please output the list of quotes using <quotes></quotes>. Respond with "No relevant quotes found!" if no relevant quotes were found.####{{document}}####
Here is a screenshot of the entire prompt including the question which is passed using the user role.
Output of Prompt 1:
<quotes>- Chain-of-thought (CoT) prompting[27]- Generated knowledge prompting[37]- Least-to-most prompting[38]- Self-consistency decoding[39]- Complexity-based prompting[41]- Self-refine[42]- Tree-of-thought prompting[43]- Maieutic prompting[45]- Directional-stimulus prompting[46]- Textual inversion and embeddings[59]- Using gradient descent to search for prompts[61][62][63][64]- Prompt injection[65][66][67]</quotes>
The quotes that were returned in the first prompt can now be used as input to the second prompt below. Note that you can clean up the quotes a bit more, i.e., remove the citations. Those citations could be removed or utilized as part of another prompt in the chain but you ignore this for now. The second prompt then takes the relevant quotes extracted by prompt 1 and prepares a helpful response to the question given the document and those extracted quotes. The second prompt can be the following:
Prompt 2:
Given a set of relevant quotes (delimited by <quotes></quotes>) extracted from a document and the original document (delimited by ####), please compose an answer to the question. Ensure that the answer is accurate, has a friendly tone, and sounds helpful.
####{{document}}####
<quotes>
- Chain-of-thought (CoT) prompting[27]
- Generated knowledge prompting[37]
- Least-to-most prompting[38]
- Self-consistency decoding[39]
- Complexity-based prompting[41]
- Self-refine[42]
- Tree-of-thought prompting[43]
- Maieutic prompting[45]
- Directional-stimulus prompting[46]
- Textual inversion and embeddings[59]
- Using gradient descent to search for prompts[61][62][63][64]
- Prompt injection[65][66][67]
</quotes>
Output of Prompt 2:
The prompting techniques mentioned in the document include:1. Chain-of-thought (CoT) prompting[27]2. Generated knowledge prompting[37]3. Least-to-most prompting[38]4. Self-consistency decoding[39]5. Complexity-based prompting[41]6. Self-refine[42]7. Tree-of-thought prompting[43]8. Maieutic prompting[45]9. Directional-stimulus prompting[46]10. Textual inversion and embeddings[59]11. Using gradient descent to search for prompts[61][62][63][64]12. Prompt injection[65][66][67]Each of these techniques employs unique strategies to enhance or specify the interactions with large language models to produce the desired outcomes.
As you can see, simplifying and create prompt chains is a useful prompting approach where the responses need to undergo several operations or transformations. As an exercise, feel free to design a prompt that removes the citations (e.g., [27]) from the response before sending this as a final response to the user of your application.
Tree of Thoughts (ToT):
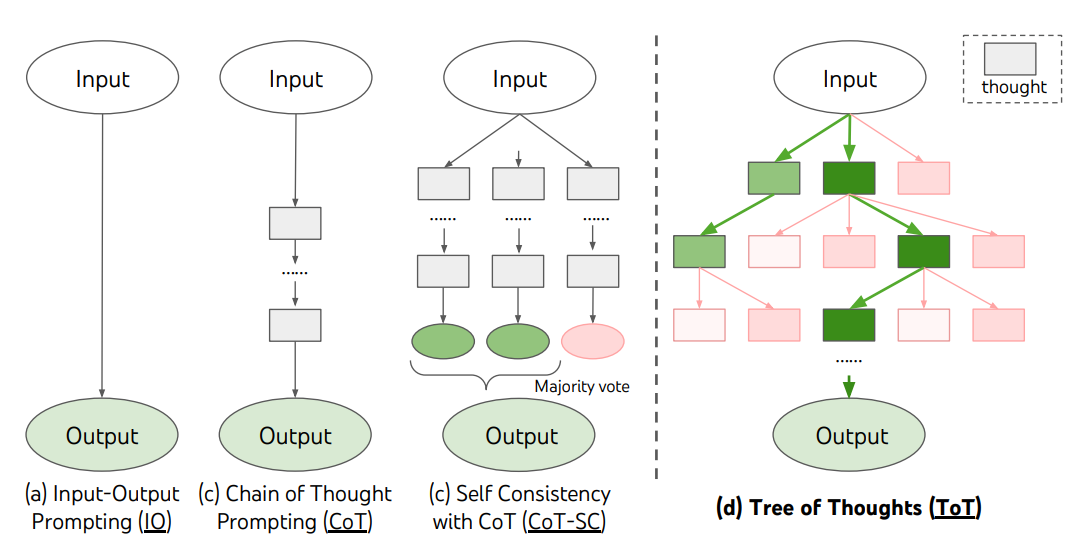
For complex tasks that require exploration or strategic lookahead, traditional or simple prompting techniques fall short. recently proposed a Tree of Thoughts (ToT), a framework that generalizes over chain-of-thought prompting and encourages exploration over thoughts that serve as intermediate steps for general problem solving with language models.
ToT maintains a tree of thoughts, where thoughts represent coherent language sequences that serve as intermediate steps toward solving a problem. This approach enables an LLM to self-evaluate the progress intermediate thoughts make towards solving a problem through a deliberate reasoning process. The LM's ability to generate and evaluate thoughts is then combined with search algorithms (e.g., breadth-first search and depth-first search) to enable systematic exploration of thoughts with lookahead and backtracking.
The ToT framework is illustrated below:
When using ToT, different tasks requires defining the number of candidates and the number of thoughts/steps. For instance, as demonstrated in the paper, Game of 24 is used as a mathematical reasoning task which requires decomposing the thoughts into 3 steps, each involving an intermediate equation. At each step, the best b=5 candidates are kept.
To perform BFS in ToT for the Game of 24 task, the LM is prompted to evaluate each thought candidate as "sure/maybe/impossible" with regard to reaching 24. As stated by the authors, "the aim is to promote correct partial solutions that can be verdicted within few lookahead trials, and eliminate impossible partial solutions based on "too big/small" commonsense, and keep the rest "maybe"". Values are sampled 3 times for each thought. The process is illustrated below:
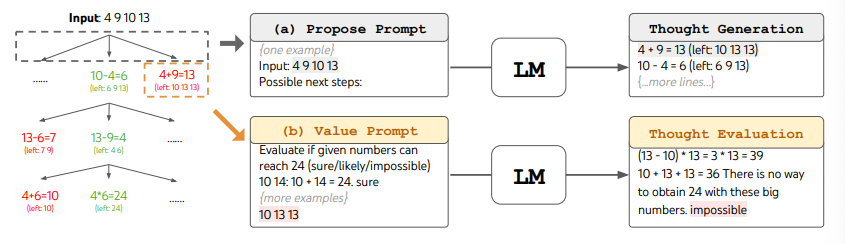
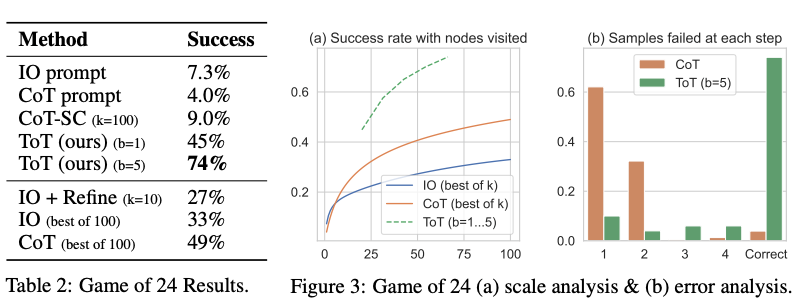
From the results reported in the figure below, ToT substantially outperforms the other prompting methods:
At a high level. Both enhance LLM's capability for complex problem solving through tree search via a multi-round conversation. One of the main difference is that Yao et el. (2023) leverages DFS/BFS/beam search, while the tree search strategy (i.e. when to backtrack and backtracking by how many levels, etc.) proposed in Long (2023) is driven by a "ToT Controller" trained through reinforcement learning. DFS/BFS/Beam search are generic solution search strategies with no adaptation to specific problems. In comparison, a ToT Controller trained through RL might be able learn from new data set or through self-play (AlphaGo vs brute force search), and hence the RL-based ToT system can continue to evolve and learn new knowledge even with a fixed LLM.
Tree-of-Thought Prompting, which applies the main concept from ToT frameworks as a simple prompting technique, getting the LLM to evaluate intermediate thoughts in a single prompt.
A sample ToT prompt is:
Imagine three different experts are answering this question.
All experts will write down 1 step of their thinking,then share it with the group.Then all experts will go on to the next step, etc.If any expert realises they're wrong at any point then they leave. The question is...
benchmarked the Tree-of-Thought Prompting with large-scale experiments, and introduce PanelGPT --- an idea of prompting with Panel discussions among LLMs.
Retrieval Augmented Generation (RAG)
General-purpose language models can be fine-tuned to achieve several common tasks such as sentiment analysis and named entity recognition. These tasks generally don't require additional background knowledge.
For more complex and knowledge-intensive tasks, it's possible to build a language model-based system that accesses external knowledge sources to complete tasks. This enables more factual consistency, improves reliability of the generated responses, and helps to mitigate the problem of "hallucination".
Meta AI researchers introduced a method called Retrieval Augmented Generation (RAG) to address such knowledge-intensive tasks. RAG combines an information retrieval component with a text generator model. RAG can be fine-tuned and its internal knowledge can be modified in an efficient manner and without needing retraining of the entire model.
RAG takes an input and retrieves a set of relevant/supporting documents given a source (e.g., Wikipedia). The documents are concatenated as context with the original input prompt and fed to the text generator which produces the final output. This makes RAG adaptive for situations where facts could evolve over time. This is very useful as LLMs parametric knowledge is static. RAG allows language models to bypass retraining, enabling access to the latest information for generating reliable outputs via retrieval-based generation.
RAG performs strong on several benchmarks such as Natural Questions, WebQuestions, and CuratedTrec. RAG generates responses that are more factual, specific, and diverse when tested on MS-MARCO and Jeopardy questions. RAG also improves results on FEVER fact verification.
This shows the potential of RAG as a viable option for enhancing outputs of language models in knowledge-intensive tasks.
More recently, these retriever-based approaches have become more popular and are combined with popular LLMs like ChatGPT to improve capabilities and factual consistency.
Active-Prompt:
Chain-of-thought (CoT) methods rely on a fixed set of human-annotated exemplars. The problem with this is that the exemplars might not be the most effective examples for the different tasks. To address this recently proposed a new prompting approach called Active-Prompt to adapt LLMs to different task-specific example prompts (annotated with human-designed CoT reasoning).
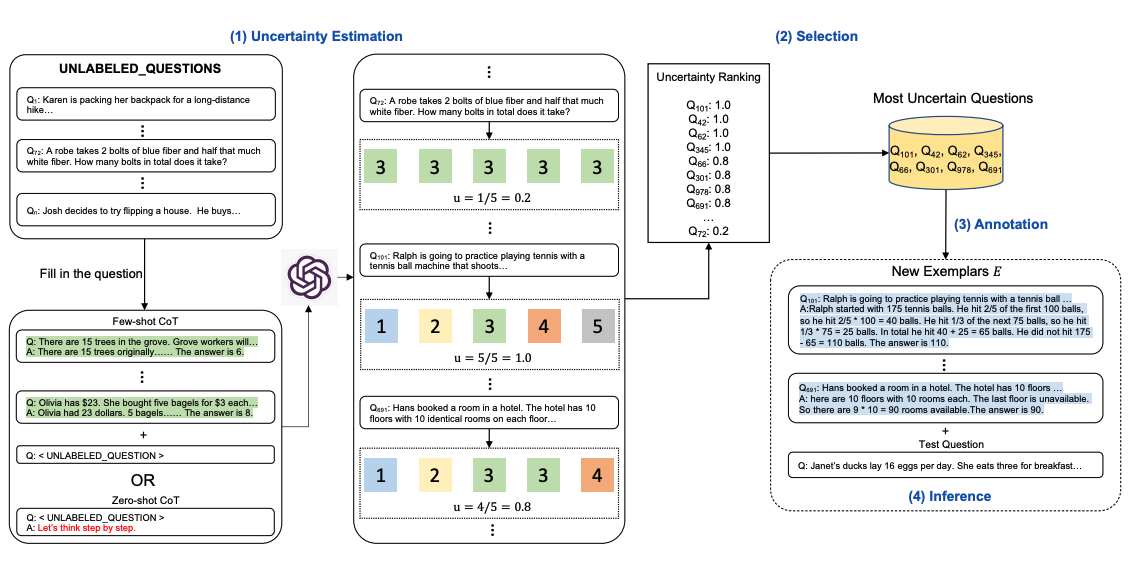
Below is an illustration of the approach. The first step is to query the LLM with or without a few CoT examples. k possible answers are generated for a set of training questions. An uncertainty metric is calculated based on the k answers The most uncertain questions are selected for annotation by humans. The new annotated exemplars are then used to infer each question.
Multimodal CoT Prompting:
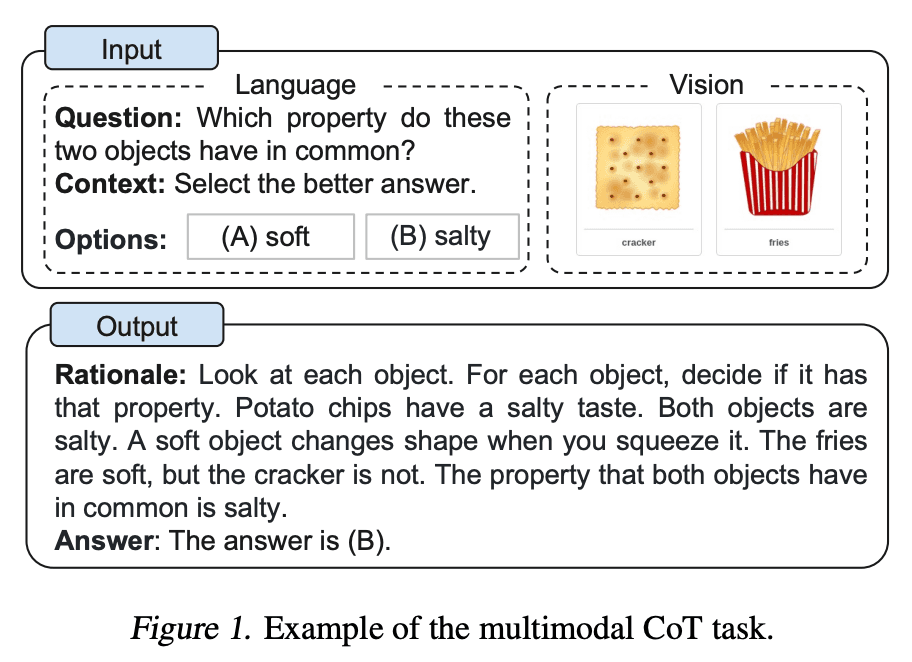
Recently proposed a multimodal chain-of-thought prompting approach. Traditional CoT focuses on the language modality. In contrast, Multimodal CoT incorporates text and vision into a two-stage framework. The first step involves rationale generation based on multimodal information. This is followed by the second phase, answer inference, which leverages the informative generated rationales.
The multimodal CoT model (1B) outperforms GPT-3.5 on the ScienceQA benchmark.
Hurray!! we've learned now how to use prompts efficiently for different Industry problems.
In next-article I'm going to dig into one of the Industry trending application ie RAG, about how to built your first RAG pipeline using llama-index with simple to advance techniques using a simple example.
So, follow me to not miss any articles on teckbakers, connect with me on linkedin, github, kaggle:)
Let's Learn and grow together:) Stay Healthy Stay Happy✨. Happy Learning!!




