

Inside the Mind of ChatGPT

Hey I'm Samiksha Kolhe. a Data Enthusiast and aspiring Data Scientist. One day Fascinated by a fact that "We can built Time machines and predict future using AI". That hit my dream to explore the Vector space and find out what the dark matter is about. World and Technology every day brings new challenges, and new learnings. Technology fascinated me, I'm constantly seeking out new challenges and opportunities to learn and grow. A born-ready girl with deep expertise in ML, Data Science, and Deep Learning, generative AI. Curious & Self-learner with a go-getter attitude that pushes me to build things. My passion lies in solving business problems with the help of Data. Love to solve customer-centric problems. Retail, fintech, e-commerce businesses to solve the customer problems using Data/AI. Currently learning MLops to build robust Data/ML systems for production-ready applications. exploring GenAI. As a strong collaborator and communicator, I believe in the power of teamwork and diversity of thoughts to solve a problem. I'm always willing to lend a helping hand to my colleagues and juniors. Through my Hashnode blog, I share my insights, experiences, and ideas with the world. I love to writing about latest trends in AI and help students/freshers to start in their AI journey. Outside technology I'm a spiritual & Yoga person. Help arrange Yoga and mediation campaigns, Volunteering to contribute for better society. Love Travelling, Reading and Learn from world.
A Sudden Boom🎇 happened in the IT Industry on Nov 30, 2022, when people started talking about the Google Replacer and the hell-giant that will take over IT jobs sooner. yess it's ChatGPT. Let's see how it came into the picture, its capabilities as compared to other GPT models, In-depth internal intuition behind its working, and some Fun!!😎 with ChatGPT.
Let's get onto it!!
What is it?
ChatGPT is the latest language model from OpenAI and represents a significant improvement over its predecessor GPT-3. Similarly to many Large Language Models, ChatGPT is capable of generating text in a wide range of styles and for different purposes, but with remarkably greater precision, detail, and coherence. It represents the next generation in OpenAI's line of Large Language Models, and it is designed with a strong focus on interactive conversations.
The creators have used a combination of both Supervised Learning and Reinforcement Learning to fine-tune ChatGPT, but it is the Reinforcement Learning component specifically that makes ChatGPT unique. The creators use a particular technique called Reinforcement Learning from Human Feedback (RLHF), which uses human feedback in the training loop to minimize harmful, untruthful, and/or biased outputs.
Okay, but, what is extraordinary in ChatGPT that makes it stand out from other GPT variants?? Let's see it first.
Why It's So Intelligent😎??
As we know, the main technology behind ChatGPT is ML/AI, hence ML works on the principle of Capability and Alignment. A model's capability is typically evaluated by how well it can optimize its objective function, the mathematical expression that defines the goal of the model. Previous GPT variants were a lot capable to withstand the sentiment, robustness and accuracy to predict the sentences. but something was missing i.e. In ML Alignment, on the other hand, is concerned with what we want the model to do versus what it is being trained to do. Large Language Models, such as GPT-3, are trained on vast amounts of text data from the internet and are capable of generating human-like text, but they may not always produce output that is consistent with human expectations or desirable values.
GPT-3 Model was misaligned.
In practical applications, however, these models are intended to perform some form of valuable cognitive work, and there is a clear divergence between the way these models are trained and the way we would like to use them. Even though a machine-calculated statistical distribution of word sequences might be, mathematically speaking, a very effective choice to model language, we as humans generate language by choosing text sequences that are best for the given situation, using our background knowledge and common sense to guide this process. This can be a problem when language models are used in applications that require a high degree of trust or reliability, such as dialogue systems or intelligent personal assistants.
Traditional Language Models like Transformers are internally based on Next-token-prediction and masked-language-modeling techniques. More generally, these training strategies can lead to a misalignment of the language model for some more complex tasks, because a model which is only trained to predict the next word (or a masked word) in a text sequence, may not necessarily be learning some higher-level representations of its meaning. As a result, the model struggles to generalize to tasks or contexts that require a deeper understanding of language.
Hence, ChatGPT is based on the original GPT-3 model but has been further trained by using human feedback to guide the learning process with the specific goal of mitigating the model’s misalignment issues. The specific technique used, called Reinforcement Learning from Human Feedback(RLHF) and ChatGPT represents the first case of use of this technique for a model put into production.
That's Why It's so Intelligent🤩.
The System-Design Of Chat-GPT
The process can be broken down into two parts:
1. Training. To train a ChatGPT model, there are two stages:
- Pre-training: In this stage, we train a GPT model (decoder-only transformer) on a large chunk of internet data. The objective is to train a model that can predict future words given a sentence in a way that is grammatically correct and semantically meaningful similar to the internet data. After the pre-training stage, the model can complete given sentences, but it is not capable of responding to questions.
- Fine-tuning: This stage is a 3-step process that turns the pre-trained model into a question-answering ChatGPT model:
1). Collect training data (questions and answers), and fine-tune the pre-trained model on this data. The model takes a question as input and learns to generate an answer similar to the training data.
2) Collect more data (questions, several answers) and train a reward model to rank these answers from most relevant to least relevant.
3) Use reinforcement learning (PPO optimization) to fine-tune the model so the model's answers are more accurate.

2. Answer a prompt
🔹Step 1: The user enters the full question, “Explain how a classification algorithm works”.
🔹Step 2: The question is sent to a content moderation component. This component ensures that the question does not violate safety guidelines and filters inappropriate questions.
🔹Steps 3-4: If the input passes content moderation, it is sent to the chatGPT model. If the input doesn’t pass content moderation, it goes straight to template response generation.
🔹Step 5-6: Once the model generates the response, it is sent to a content moderation component again. This ensures the generated response is safe, harmless, unbiased, etc.
🔹Step 7: If the input passes content moderation, it is shown to the user. If the input doesn’t pass content moderation, it goes to template response generation and shows a template answer to the user.
Now, Let's see The main Backbones of ChatGPT i.e. GPT-3.6, RLHF, and Prompt Engineering.
1. What Is GPT??
GPT stands for Generative Pre-trained Transformer. It is trained to predict the next word given a sentence. The GPT-2 with 15M parameters was trained on a massive 40GB dataset called WebText that the OpenAI researchers crawled from the internet as part of the research effort. further GPT-3 come up with 175 billion parameters and was recognized as the biggest neural network ever created as of early 2021.
Further to overcome the misalignment problem in GPT-3, GPT-3.6 came ie. ChatGPT. Now, GPT-4 is Expected to release in the first quarter of 2023 and will come with more advancements.
GPT is the underlying model behind any LLM, but let's see what's new spice added in chatgpt i.e. Reinforcement Learning from Human Feedback(RLHF)
2. Reinforcement Learning from Human Feedback(RLHF)
The method overall consists of three distinct steps:
Supervised fine-tuning step: a pre-trained language model is fine-tuned on a relatively small amount of demonstration data curated by labelers, to learn a supervised policy (the SFT model) that generates outputs from a selected list of prompts. This represents the baseline model.
“Mimic human preferences” step: labelers are asked to vote on a relatively large number of the SFT model outputs, this way creating a new dataset consisting of comparison data. A new model is trained on this dataset. This is referred to as the reward model (RM).
Proximal Policy Optimization (PPO) step: the reward model is used to further fine-tune and improve the SFT model. The outcome of this step is the so-called policy model.
Step 1 takes place only once, while steps 2 and 3 can be iterated continuously: more comparison data is collected on the current best policy model, which is used to train a new reward model and then a new policy.
Let’s now dive into the details of each step!!
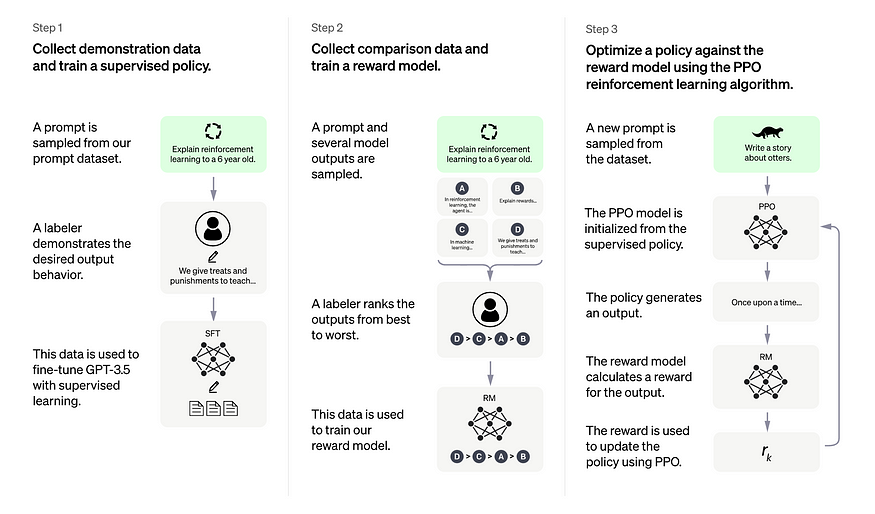
- Step 1: The Supervised Fine-Tuning (SFT) model
The first step consists in collecting demonstration data to train a supervised policy model, referred to as the SFT model.
Data collection: a list of prompts is selected and a group of human labelers are asked to write down the expected output response. For ChatGPT, two different sources of prompts have been used: some have been prepared directly from the labelers or developers, some have been sampled from OpenAI’s API requests (i.e. from their GPT-3 customers). As this whole process is slow and expensive, the result is a relatively small, high-quality curated dataset (of approximately 12-15k data points, presumably) that is to be used to fine-tune a pretrained language model.
Choice of model: instead of fine-tuning the original GPT-3 model, the developers of ChatGPT opted for a pre-trained model in the so-called GPT-3.5 series. Presumably, the baseline model used is the latest one
text-davinci-003, a GPT-3 model which was fine-tuned mostly on programming code.
Quite interestingly, therefore, in order to create a general purpose chatbot like ChatGPT, the developers decided to fine-tune on top of a “code model” rather than a pure text model.
Due to the limited amount of data for this step, the SFT model obtained after this process is likely to output text which is still (probabilistically) not very user-attentive and generally suffers from misalignment, in the sense explained in the above sections. The problem here is that the supervised learning step suffers from high scalability costs.
To overcome this problem, instead of asking human labelers to create a much bigger curated dataset, a slow and costly process, the strategy is now to have the labelers rank different outputs of the SFT model to create a reward model –let’s explain this in more detail in the following section.
- Step 2: The reward model (RM): refer to figure-1
The goal is to learn an objective function (the reward model) directly from the data. The purpose of this function is to give a score to the SFT model outputs, proportional to how desirable these outputs are for humans. In practice, this will strongly reflect the specific preferences of the selected group of human labelers and the common guidelines which they agreed to follow. In the end, this process will extract from the data an automatic system that is supposed to mimic human preferences.
Here’s how it works:
A list of prompts is selected and the SFT model generates multiple outputs (anywhere between 4 and 9) for each prompt.
Labelers rank the outputs from best to worst. The result is a new labeled dataset, where the rankings are the labels. The size of this dataset is approximately 10 times bigger than the curated dataset used for the SFT model.
This new data is used to train a reward model (RM). This model takes as input a few of the SFT model outputs and ranks them in order of preference.
As for labelers it is much easier to rank the outputs than to produce them from scratch, this process scales up much more efficiently. In practice, this dataset has been generated from a selection of 30-40k prompts, and a variable number of the generated outputs (for each prompt) is presented to the each labeler during the ranking phase.
Step 3: Fine-tuning the SFT model via Proximal Policy Optimization (PPO)
Reinforcement Learning is now applied to fine-tune the SFT policy by letting it optimize the reward model. The specific algorithm used is called Proximal Policy Optimization (PPO) and the fine-tuned model is referred to as the PPO model.
What is PPO? Here are the main takeaways of this method:
PPO is an algorithm that is used to train agents in reinforcement learning. It is called an "on-policy" algorithm because it learns from and updates the current policy directly, rather than learning from past experiences as in "off-policy" algorithms like DQN (Deep Q-Network). This means that PPO is continuously adapting the current policy based on the actions that the agent is taking and the rewards it is receiving.
PPO uses a trust region optimization method to train the policy, which means that it constrains the change in the policy to be within a certain distance of the previous policy in order to ensure stability. This is in contrast to other policy gradient methods which can sometimes make large updates to the policy that can destabilize learning.
PPO uses a value function to estimate the expected return of a given state or action. The value function is used to compute the advantage function, which represents the difference between the expected return and the current return. The advantage function is then used to update the policy by comparing the action taken by the current policy to the action that would have been taken by the previous policy. This allows PPO to make more informed updates to the policy based on the estimated value of the actions being taken.
In this step, the PPO model is initialized from the SFT model, and the value function is initialized from the reward model. The environment is a bandit environment that presents a random prompt and expects a response to the prompt. Given the prompt and response, it produces a reward (determined by the reward model) and the episode ends. A per-token KL penalty is added from the SFT model at each token to mitigate over-optimization of the reward model.
3. Prompt Engineering
Prompt engineering is set to become one of the most in-demand skill sets. In the near future, people will move away from using search engines and rely more on AI chatbots for their queries, with ChatGPT serving as a good example.
Prompt engineering can be compared to building a set of road signs for a chatbot. Just as road signs provide clear direction and guidance to drivers, prompts in a chatbot help guide the user towards their desired outcome. The goal is to make the prompts as clear and effective as possible, so that the user can reach their desired outcome with minimal confusion.
The key to writing effective prompts is understanding what the AI chatbot knows about the world and how to use that information to generate useful results. A skilled prompt engineer will even be able to manipulate the AI to produce outcomes of their choice, making them the "hackers" of the AI world in the future.
Performance Evaluation
The model is evaluated on three high-level criteria:
Helpfulness: judging the model’s ability to follow user instructions, as well as infer instructions.
Truthfulness: judging the model’s tendency for hallucinations (making up facts) on closed-domain tasks. The model is evaluated on the TruthfulQA dataset.
Harmlessness: the labelers evaluate whether the model’s output is appropriate, denigrates a protected class, or contains derogatory content. The model is also benchmarked on the RealToxicityPrompts and CrowS-Pairs datasets.
The model is also evaluated for zero-shot performance on traditional NLP tasks like question answering, reading comprehension, and summarization, on some of which the developers observed performance regressions compared to GPT-3. This is an example of an “alignment tax” where the RLHF-based alignment procedure comes at the cost of lower performance on certain tasks.
There's yet to come more... hope you like this article, Stay tuned, make sure to subscribe our newsletter for more such articles. follow me on Linkedin, github. always welcome for any sugesstions:)
happy Reading!!




