


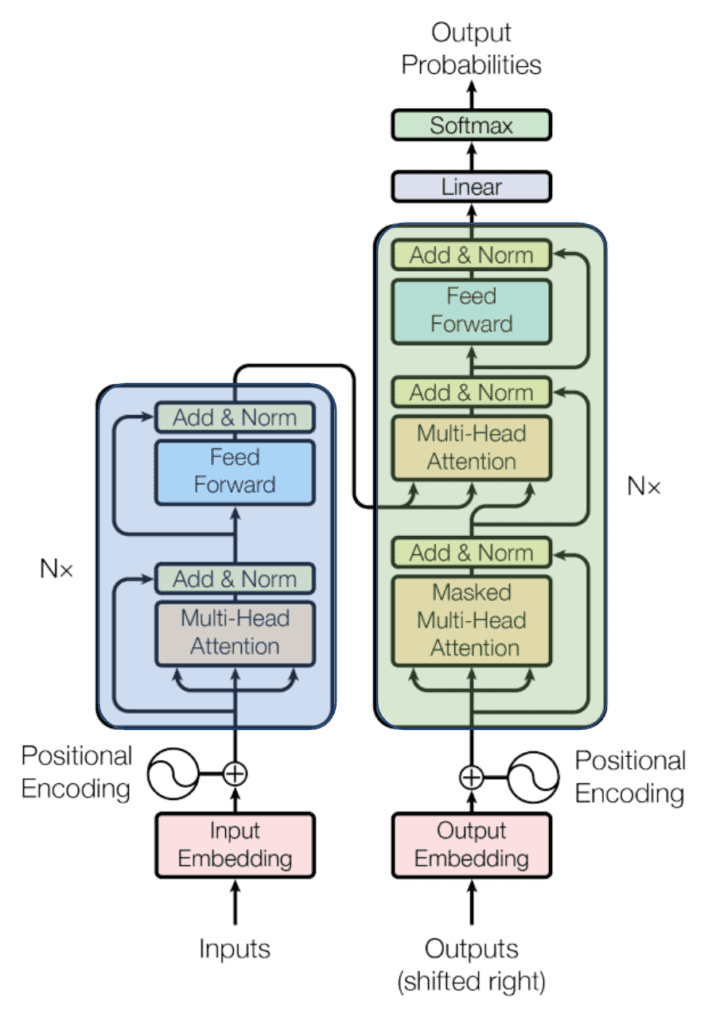
Transformers: Understand the Base Architecture behind GPT, Llama, Mixtral...


Hello Techies👋! Hope you all are doing amazing stuff. I'm back with another amazing and trending stuff in market today. Yes, I'm going to discuss the Revolutionary Transformer architecture that is backed by every LLM model available today!!
Sounds Exciting!!🤩
Note: This Article will be a bit more technical and Architecture oriented. I'll discuss the working through a simple Language Translation example to get an overall idea.
What you'll learn from this article:
How it all started-> Self-attention in detail.
Transformer components in detail i.e. every bit of Encoder and Decoder Architecture.
What are Foundational Models?
How Transformers work at training time
How transformers work at Inference time.
Bonus: Innovative Architecture by Mistral: Mixture of experts(MOE) by Mixtral8X7
Let's get into it!!
Transformer architecture is first proposed in the "Attention is all you need" paper. which discusses about adding the self-attention to encoder-decoder architecture used with LSTM's which means to make model more context-rich by focusing on every word and finding it's relationship with it's previous words.
In large language models, You must have heard the below terminologies.
"encoder only": full encoder, full decoder.
"encoder-decoder": full encoder, autoregressive decoder.
"decoder only": autoregressive encoder, autoregressive decoder.
Here "autoregressive" means that a mask is inserted in the attention head to zero out all attention from one token to all tokens following it.
Generally, Transformer-based language models are of two types: causal (or "autoregressive") and masked. The GPT series is causal and decoder only. BERT is masked and encoder only. The T5 series is encoder-decoder, with a full encoder and autoregressive decoder, discussed in detail in future.
The Heart of Transformer i.e. Self attention allows the model to focus on different parts of the input sequence when processing each element. to capture the semantic meaning of the sentence. Let's discuss in-detail further.
Self Attention Is All you Need
Let's discuss in-detail Maths behind self-attention Concept.

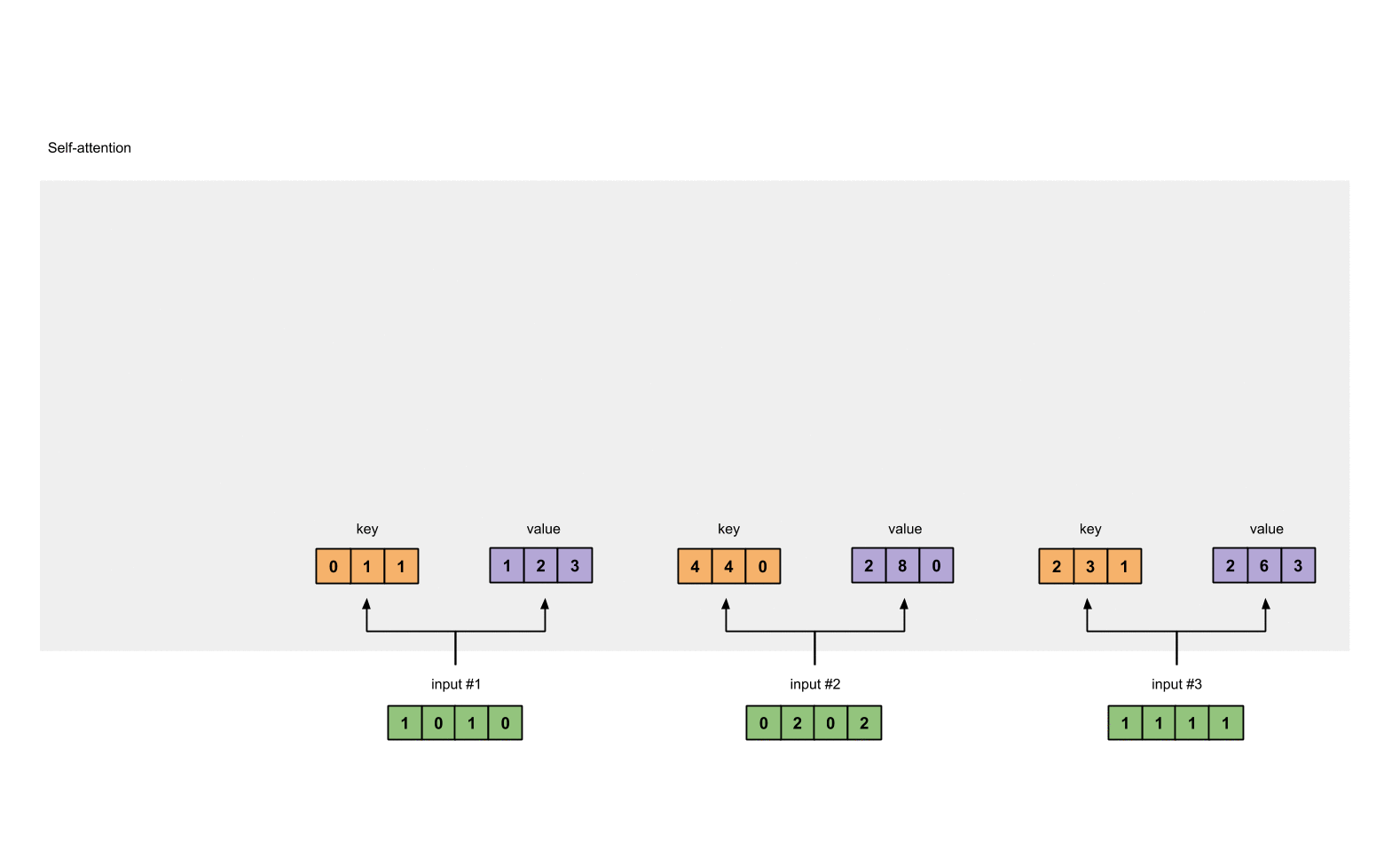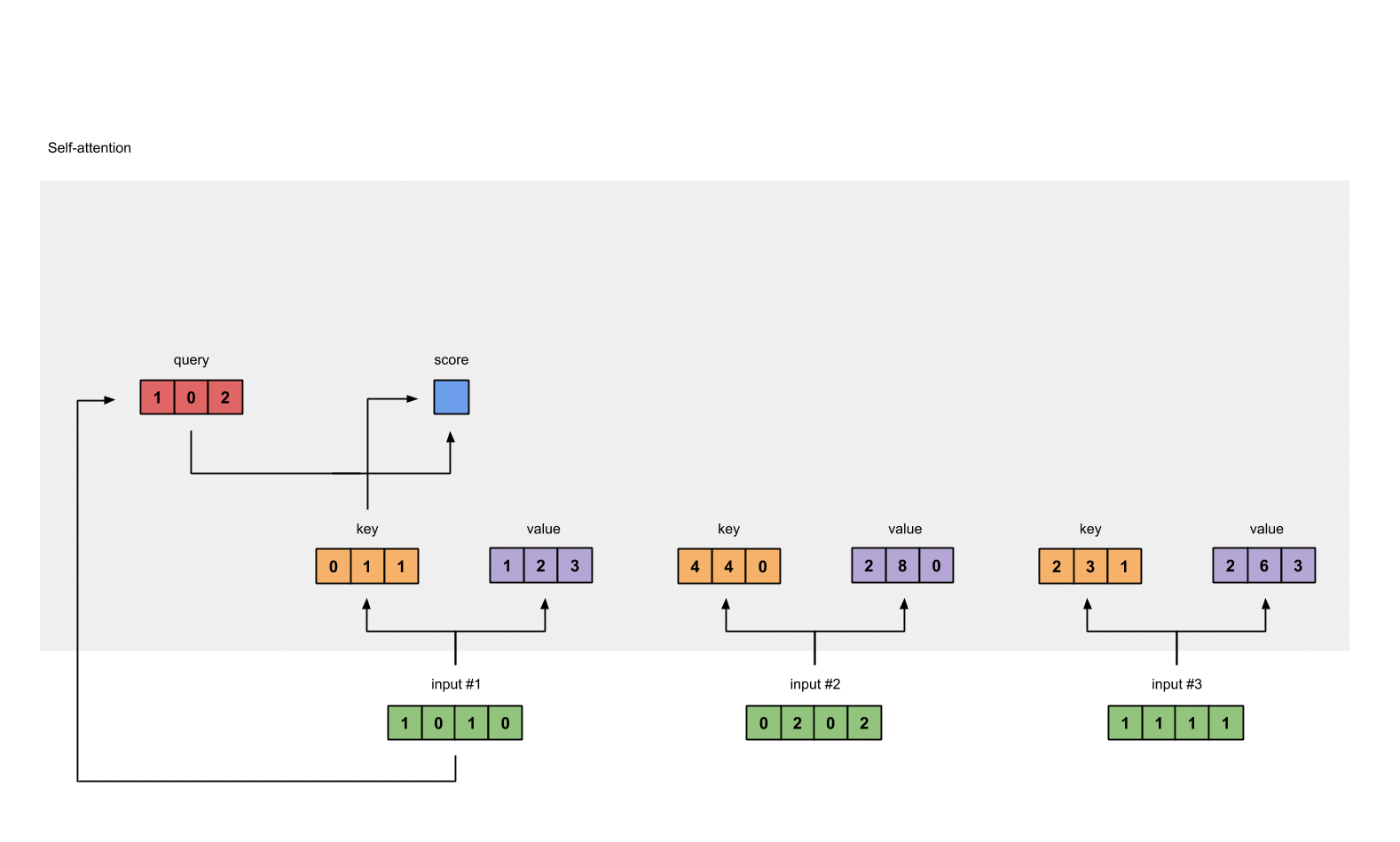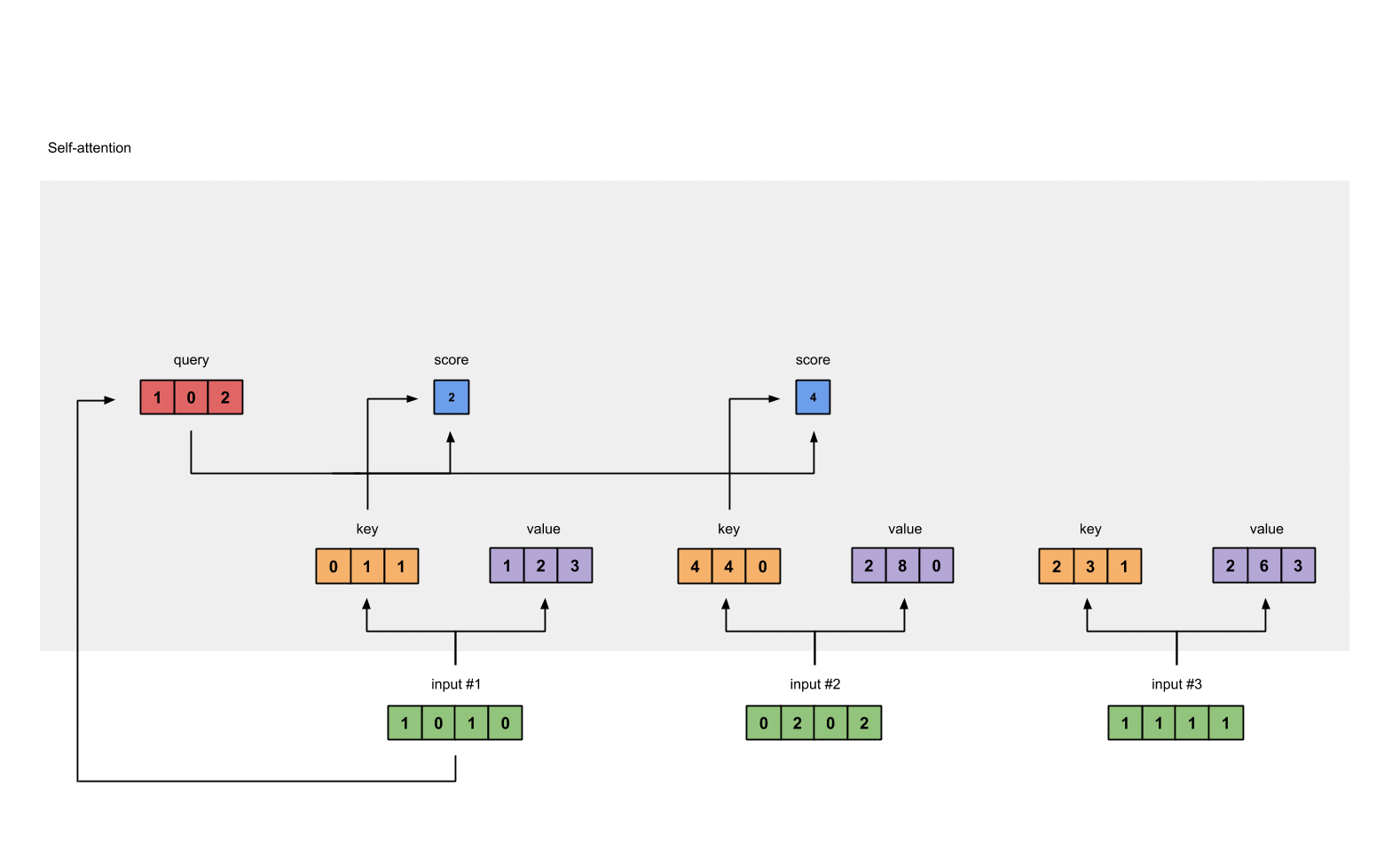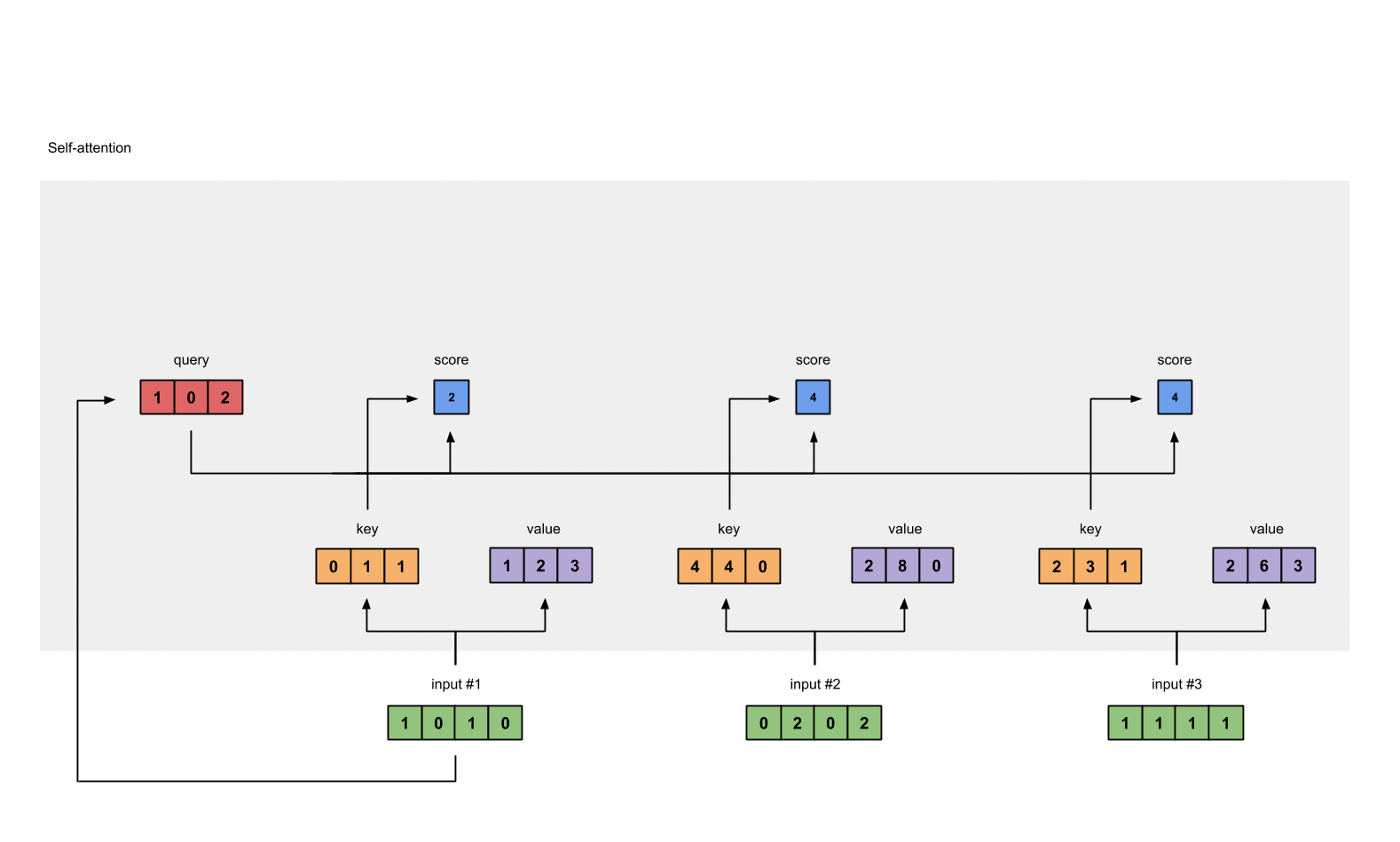
Let’s consider the example of a language translation task using a transformer model to understand self-attention step by step.
Suppose we want to translate the sentence: “The cat sat on the mat.”
Encoding the Input: Firstly, the input sentence is encoded into a sequence of word embeddings. There's a whole lot of process happens to convert a subword/word/sentence into an embedding known as Tokenization (raw text to numeric representation). I've already created in-depth understanding and various types of tokenizer algorithms used by Most popular LLM's today, checkout the article here!!.
Each word is represented as a high-dimensional vector, capturing its semantic meaning.
Example: [Embedding for 'The', Embedding for 'cat', Embedding for 'sat',
Embedding for 'on', Embedding for 'the', Embedding for 'mat',
Embedding for '.']
Creating Queries, Keys, and Values: Next, the self-attention mechanism generates three versions of the input embeddings: queries, keys, and values. These are linear projections of the original embeddings and are used to calculate attention scores.
Query = New token of a sequence -> a 1D array
Key = Previous context that model should attend i.e. previous tokens knowledge -> A matrix.
Value = Weighted sum over the previous context.

Queries: [Query for 'The', Query for 'cat', Query for 'sat',
Query for 'on', Query for 'the', Query for 'mat', Query for '.']
Keys: [Key for 'The', Key for 'cat', Key for 'sat', Key for 'on',
Key for 'the', Key for 'mat', Key for '.']
Values: [Value for 'The', Value for 'cat', Value for 'sat',
Value for 'on', Value for 'the', Value for 'mat', Value for '.']
Random data:
Queries: [[0.23,0.4,.67,....],[0.4,0.6,.67,....],[0.2,0.2,.67,....],
[0.5,0.3,.8,....], [0.1,0.4,.67,....], [0.2,0.4,.67,....],
[0.7,0.4,.6,....]]
Keys: [[0.1,0.4,.5,....],[0.2,0.4,.67,....],[0.3,0.4,.67,....],
[0.4,0.4,.67,....], [0.5,0.4,.67,....], [0.6,0.7,.8,....],
[0.6,0.4,.8,....]]
Values: [[0.4,0.5,.67,....],[0.23,0.4,.5,....],[0.23,0.4,.8,....],
[0.23,0.4,.45,....], [0.23,0.4,.9,....], [0.23,0.4,.6,....],
[0.23,0.4,.10,....]]
Calculating Attention Scores: Attention scores are calculated by taking the dot product of a query with the keys. These scores represent the importance or relevance of each word to the current word being processed.
Randoms Scores
Example: Attention scores for 'The': [0.9,0.7,0.5, 0.4,0.45,0.56,0.23]
Attention scores for 'cat': [0.6,0.5,0.7, 0.23,0.44,0.58,0.23]
.....
Attention scores for '.': [0.3,0.5,0.9, 0.4,0.45,0.56,0.23]
Applying Softmax: Softmax function is applied to the attention scores to convert logits (raw output) into probabilities. This ensures that the attention weights sum up to 1 and indicate the relative importance of each word in the context of the current word.
- Take the softmax across these attention scores (blue).


Step 6 : Multiply scores with values
The softmax attention scores for each input (blue) is multiplied by its corresponding value (purple). This results in 3 vectors (yellow).


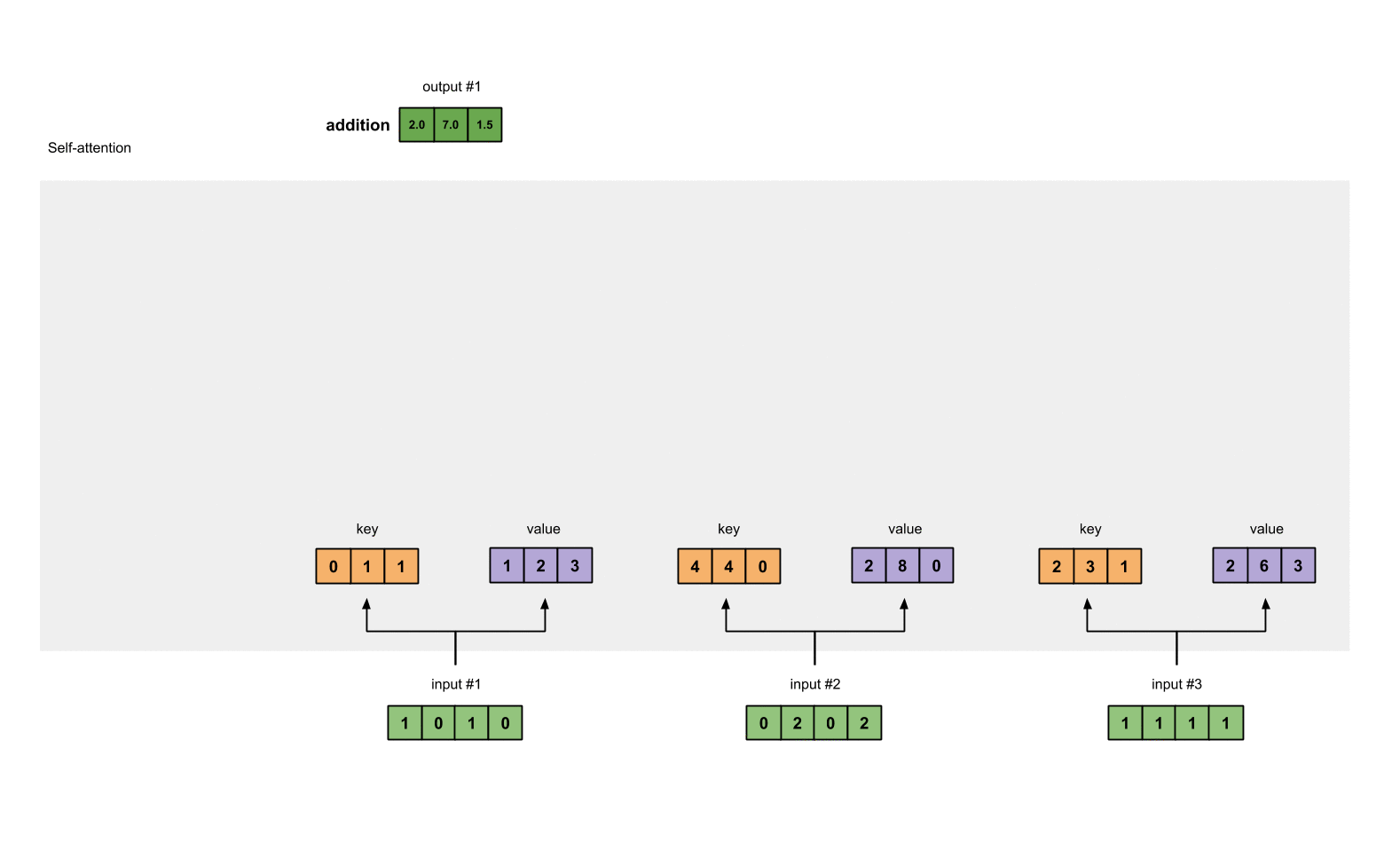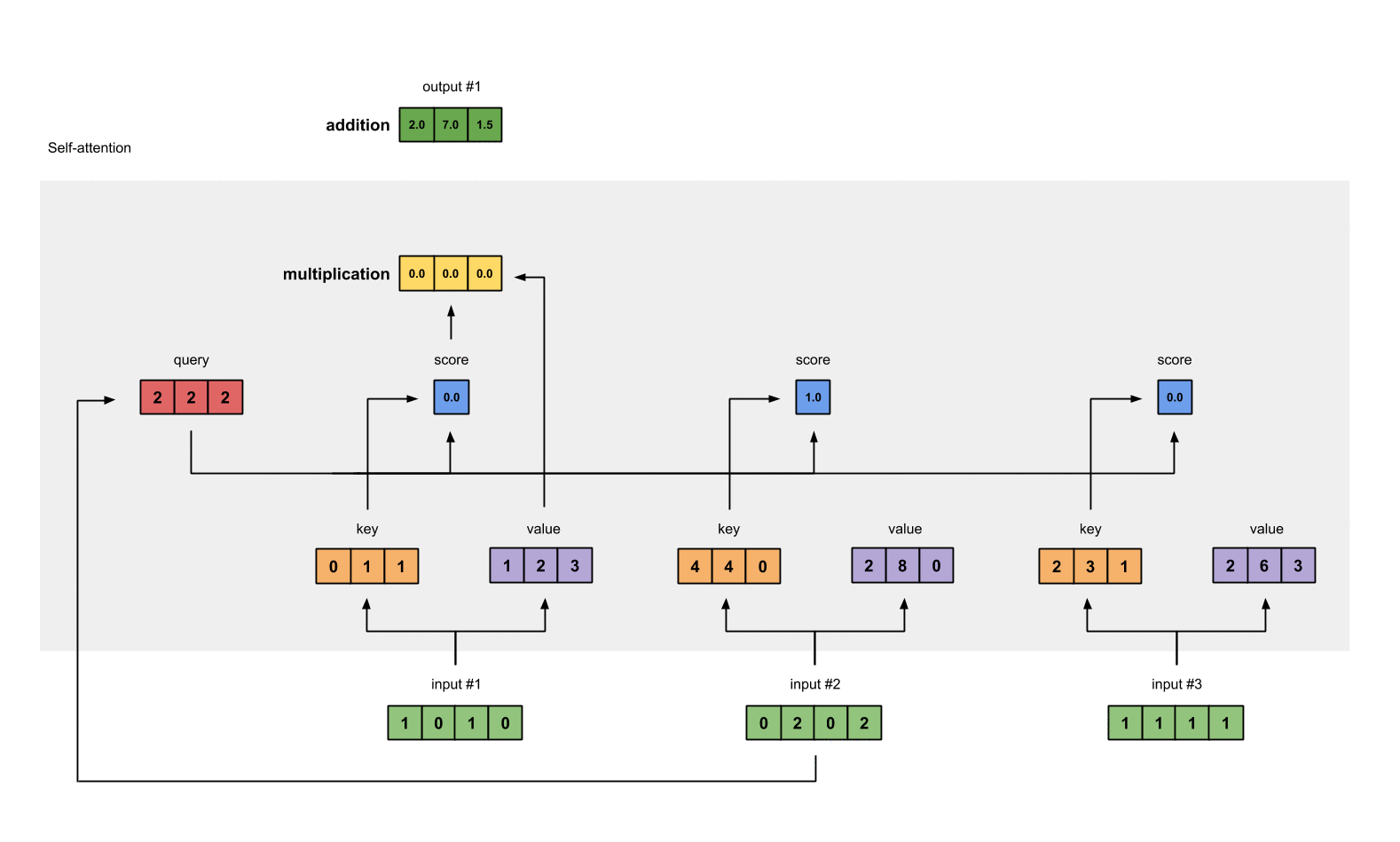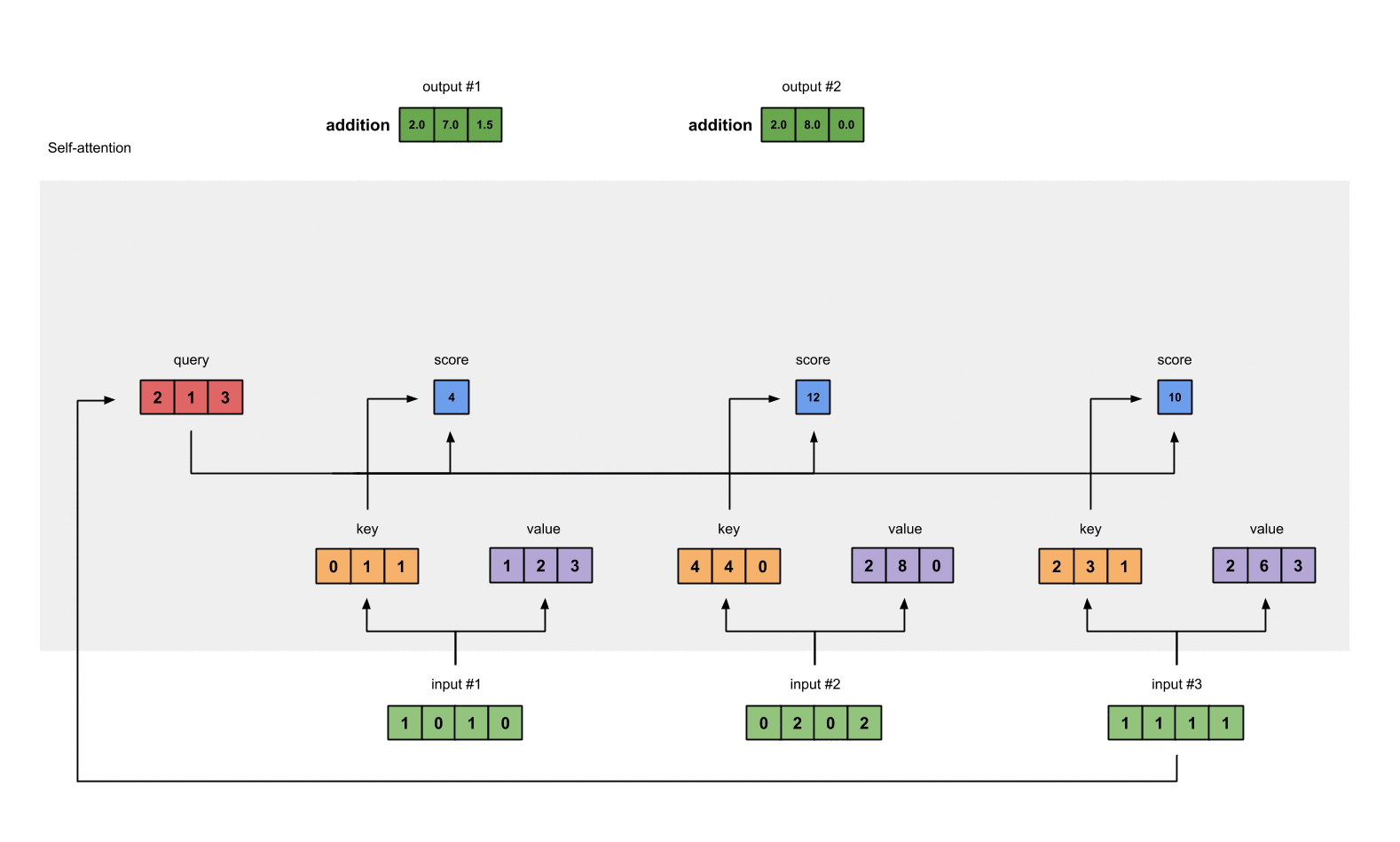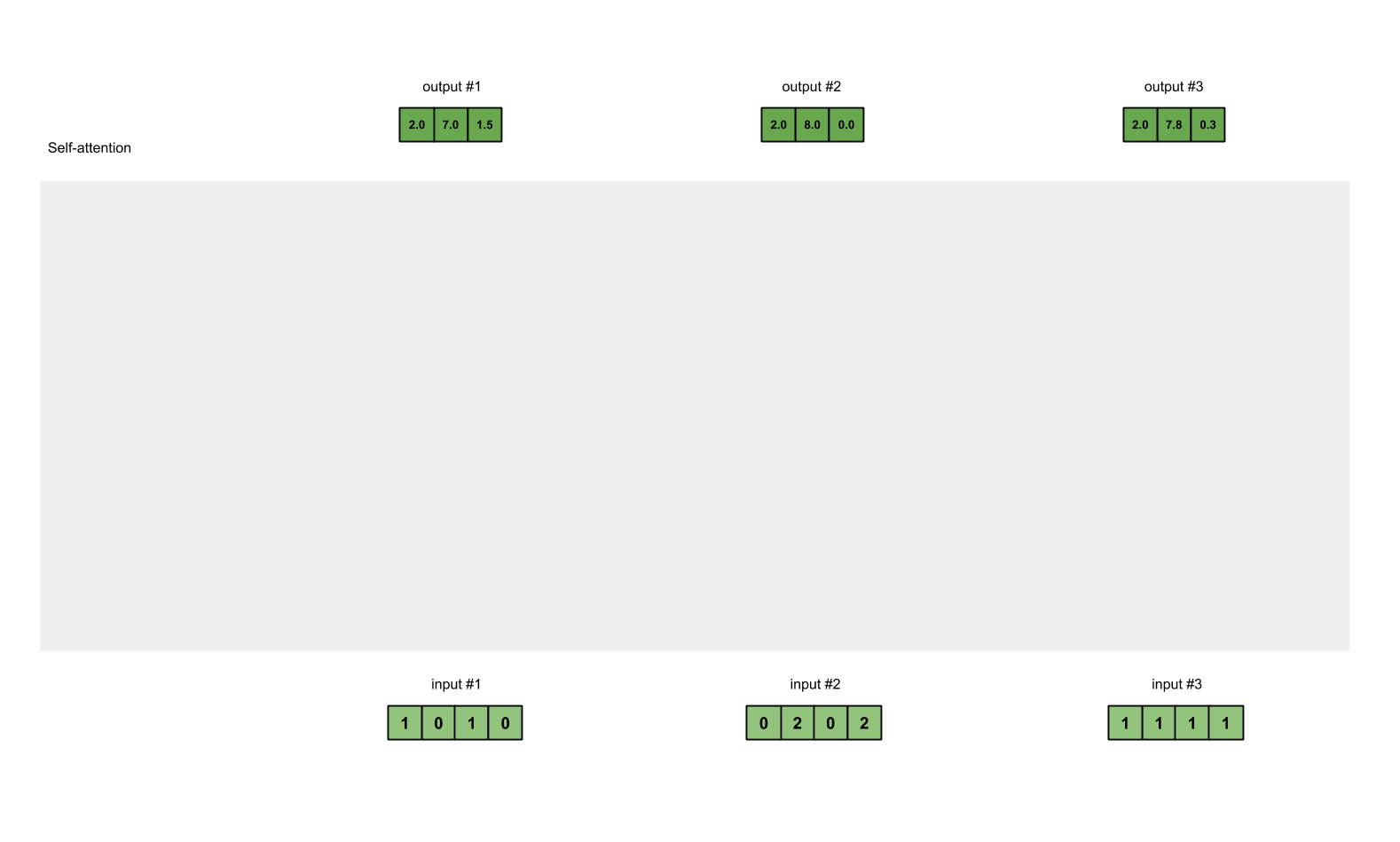
Weighted Sum of Values: Finally, the softmax attention scores are used to compute a weighted sum of the values. The resulting vector represents the context-aware representation of the current word, considering its relationship with other words in the sequence.

Take all the weighted values (yellow) and sum them element-wise:

The resulting vector [2.0, 7.0, 1.5] (dark green) is Output 1, which is based on the query representation from Input 1 interacting with all other keys, including itself.
Repeat for input 2 and input 3
We have explained how to get output #1. We need to do the same for output #2 and output #3.
Example: Context-aware representation : [0.29 * Value for 'The' + 0.1 * Value for 'cat' + 0.12 * Value for 'sat' + …]
This output representation captures the contextual information for all the words by considering their relationship with other words in the sentence. You will get a 2D matrix after multiplying with the values.
By applying self-attention, the transformer model can capture the dependencies between different words in the input sequence and learn to focus on the most relevant words for each position. This helps in understanding the context and improving the quality of translation or any other sequence-based tasks.
Now you got to know self-attention mechanism and how transformer model can able to capture the semantic meaning of the sentence or Text.
Transformer Components
Transformer is made up of two main components, Encoder and Decoder.
Encoder:
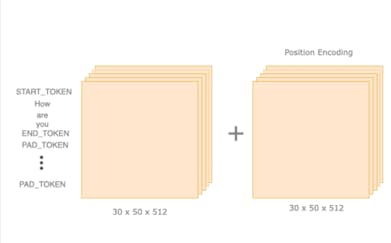
Encoder as per it's name, it encodes the data in simple terms it converts your raw text vector(Output after tokenization) into context-rich embeddings. You can see below a <START_TOKEN> <END_TOKEN> are assign for a sentence to capture the semantic meaning of the sentence. <PAD_TOEN> is added extra to match the input sequence to the transformer model i.e. Each sentence within the corpus should be of the same length.
Create a stack of all sentences cuz, as we know transformers do parallel processing. The transformer architecture was able to process 512 sequences at a time.
Then comes the next concept Positional Encoding. checkout the positional encoding blog, where in discussed in-depth Maths understanding of how positions of tokens or sentences get differed and calculated.
Positional Embeddings
Once we have the vectors corresponding to each of the tokens in the sentence, the next step is to turn all these into one vector to process. The most common way to turn a bunch of vectors into one vector is to add them, component-wise. That means, we add each coordinate separately. For example, if the vectors (of length 2) are [1,2], and [3,4], their corresponding sum is [1+3, 2+4], which equals [4, 6]. This can work, but there’s a small caveat. Addition is commutative, meaning that if you add the same numbers in a different order, you get the same result. In that case, the sentence “I’m not sad, I’m happy” and the sentence “I’m not happy, I’m sad”, will result in the same vector, given that they have the same words, except in different order. This is not good. Therefore, we must come up with some method that will give us a different vector for the two sentences. Several methods work, and we’ll go with one of them: positional encoding. Positional encoding consists of adding a sequence of predefined vectors to the embedding vectors of the words. This ensures we get a unique vector for every sentence, and sentences with the same words in different order will be assigned different vectors. In the example below, the vectors corresponding to the words “Write”, “a”, “story”, and “.” become the modified vectors that carry information about their position, labeled “Write (1)”, “a (2)”, “story (3)”, and “. (4)”.
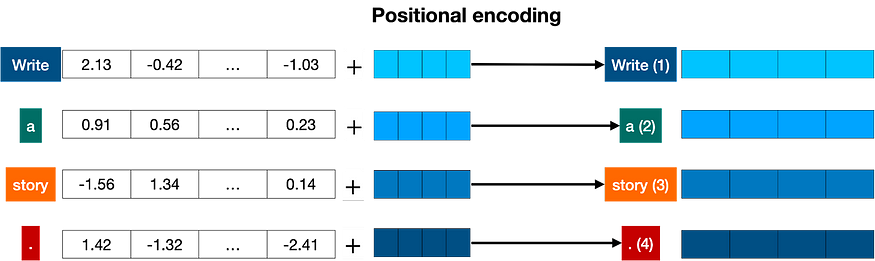
Positional encoding adds a positional vector to each word, in order to keep track of the positions of the word.
Now after getting positional rich vector of our text, next thing is to add semantic meaning to the positional vectors.
The Position aware embeddings are then passed through Multi-headed attention.
Multi-headed attention
A for loop over self-attention
Roughly speaking we can look at multi-headed attention as a big for loop over self-attention. During training phase generally in the base transformer architecture 8 Multi-head attention layers are added, It differs as per model training. We call one attention calculation a head and multi-head calculation is doing it multiple times.

The only thing that is different, are our WQ, WK, WV matrices and these are separate matrices for each head.

The paper further refined the self-attention layer by adding a mechanism called “multi-headed” attention. If we have 2 “heads” then we get the following.
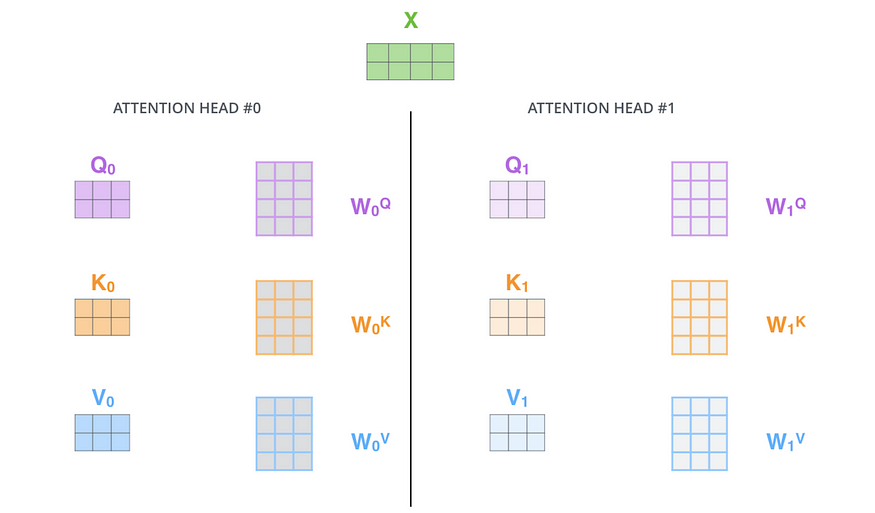
We can calculate these heads separately / in parallel because they have separate learned WQ, WK and WV matrices. Each of those were initialized randomly and give different results with the backpropagation optimization.
This is all great but one head in the attention model did the following:
We had in input vector of size 4 (4 dimensions) for each input word. If we have 2 words in our sentence, then our input is a 2x4 matrix :

After one attention head we had an output vector with the size of number of words/ input for each input vector and this gets stacked (Z — > 2 x 3 matrix)

So if we have input vectors of size 4 and if we have 2 words/input vectors in our sentences, then we get back a 2x3 attention head matrix for each attention head (8 2x3 matrices in the picture above).
This leaves us with a bit of a challenge. The next layer (feed-forward layer) is expecting a single matrix (each word has a single vector representation).
The solution is simple…
We concatenate all the attention heads
We multiply it with a new learnable weight matrix W
Our result of the multiplication is Z (which has the same dimensions as our input)
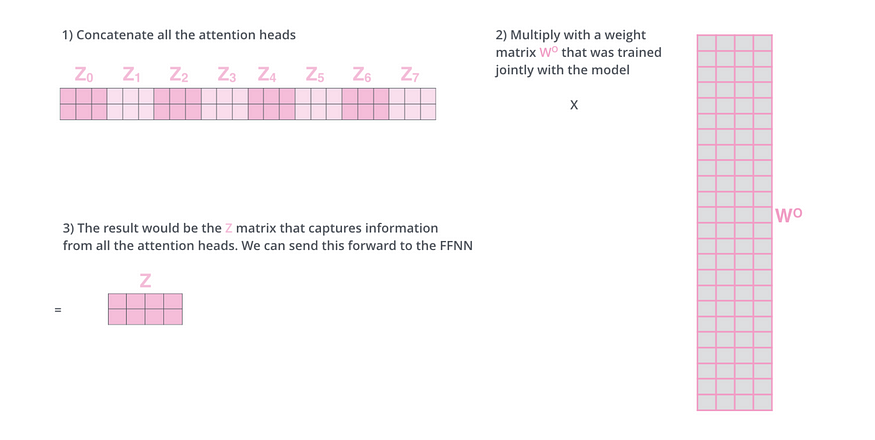
So if we put it all together in one overview with a simple input sentence of 2 words (“thinking machines”).

And again we can see that output Z has the same dimensions as X and this is great if we want to stack multiple similar encoding blocks on top of each other.
Layer Normalization
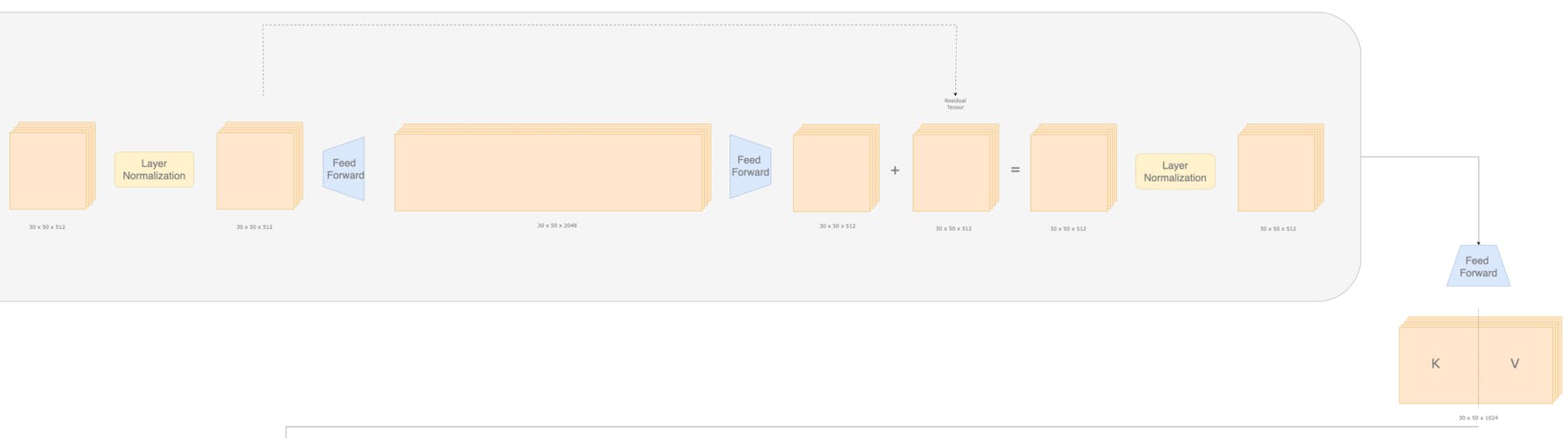
In the above schema we can see a lot of “Add & Norm” components. These are actually normalization layers which is shown in detail below.
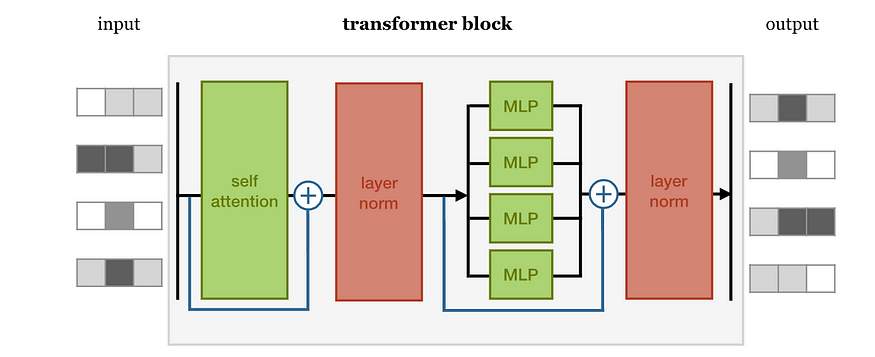
So what is their purpose? Why do we use them a lot in the architecture?
Normalization is a step that pairs well with skip connections. There’s no reason they necessarily have to go together, but they both do their best work when placed after a group of calculations, like attention or a feed forward neural network.
The short version of layer normalization is that the values of the matrix are shifted to have a mean of zero and scaled to have a standard deviation of one.
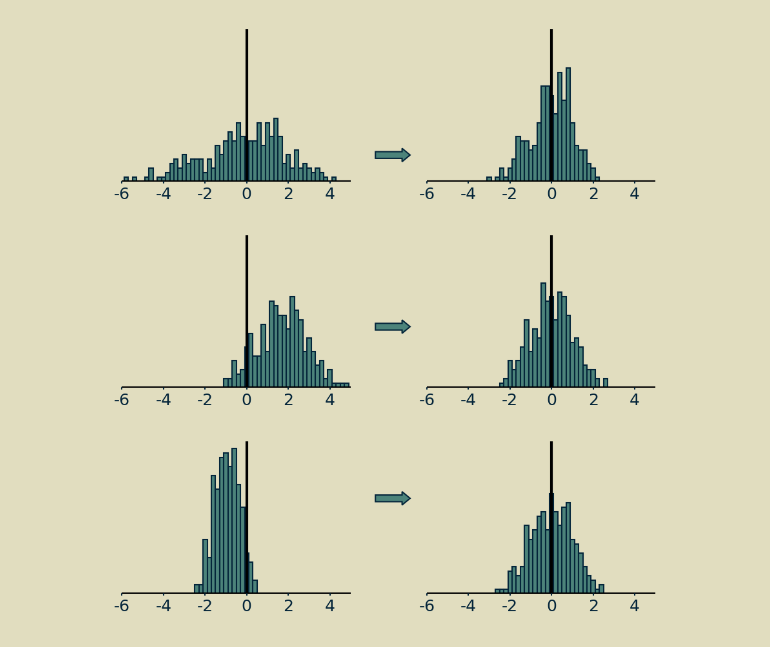
The longer version is that in systems like transformers, where there are a lot of moving pieces and some of them are something other than matrix multiplications (such as softmax operators or ReLu), it matters how big values are and how they’re balanced between positive and negative.
If everything is linear, you can double all your inputs, and your outputs will be twice as big, and everything will work just fine. Not so with neural networks.
They are inherently nonlinear, which makes them very expressive but also sensitive to signals’ magnitudes and distributions. Normalization is a technique that has proven useful in maintaining a consistent distribution of signal values each step of the way throughout many-layered neural networks. It encourages convergence of parameter values and usually results in much better performance.
Masking in Encoder is optional, cuz, encoder work is to only generate context rich vector embeddings, will discuss in-detail How masked Self-attention is works in Decoder component.
Feed Forward Neural Networks
Feedforward is a concept that originates from the field of neural networks. In essence, it refers to the process of passing information forward through the network, from the input layer, through the hidden layers, and finally to the output layer.
Unlike recurrent neural networks, where information can loop back through the network, in a feedforward network, information only moves in one direction: forward.
The Feedforward operation is a crucial part of the Transformer’s architecture because it allows the model to learn complex patterns and relationships in the data. Without the Feedforward operation, the Transformer would be much less powerful and versatile. But why is it so important? Let’s delve deeper into the reasons.
- Enabling Deeper Networks
The Feedforward operation enables the creation of deeper networks. Deeper networks have more layers and therefore more capacity to learn complex patterns in the data. However, training deeper networks can be challenging due to issues such as vanishing or exploding gradients.
The Feedforward operation, combined with techniques such as batch normalization and residual connections, can help mitigate these issues and make it possible to train deeper networks. This is another reason why the Feedforward operation is a crucial part of the Transformer’s architecture.
- Compatibility with Other Operations
In a Transformer, the self-attention mechanism allows the model to focus on different parts of the input sequence when producing the output sequence. The Feedforward operation then transforms this output into the final output of the model.
This compatibility is important because it allows the Transformer to combine the strengths of different operations. The self-attention mechanism allows the model to handle long-range dependencies in the data, while the Feedforward operation allows the model to learn complex patterns.
Decoder
The decoder is pretty much the same as the encoder when dealing with attention. The big difference is that the decoder is autoregressive like already mentioned (it gets the previous decoder output as input).

This has the consequence that it generates the sequence word by word, you need to prevent it from conditioning to future tokens. that's where the causal masking comes into the picture.

For example, when computing attention scores on the word “am”, you should not have access to the word “fine”, because that word is a future word that was generated after. The word “am” should only have access to itself and the words before it. This is true for all other words, where they can only attend to previous words.
We need a method to prevent computing attention scores for future words. This method is called masking. In a nutshell we are making sure that those attention scores are zero. The mask is added before calculating the softmax, and after scaling the scores.
So, as you have seen below in the transformer architecture, decoder takes input word by word one after the other. So, Encoder gives us the rich set of embeddings and then as per the type of task, decoder autoregressively predicts the next token in the input sequence.

Now, As the decoder predicts the next word and chooses the best possible next token from the vocabulary or text embedding that model is getting feeded by encoder. How a decoder chooses the best token? Basically, it makes use of Token sampling techniques, Some common sampling techniques that is evolved over the years are greedy decoding, Exhaustive Search Decoding, beam search, constrained beam search, Banking and now latest top-k and top-p. These sampling stratergies like top-p, top-k and temperature you must have seen while working on OpenAI completion models. I'm not going in-detail inside the each of the techniques, if you wanted to know in-depth on how each decoding evolves and helps us to get deterministic or creative best answers by tuning these parameters, checkout this blog on token-sampling techniques.
Key Learning: Decoder Takes input embeddings(matrics of vectors)from the encoder -> feeds to multi-head attention layer (combines input word vector dot product with Embedding vectors) -> layer_normalisation -> feed-forward network -> softmax(Logits) -> token_sampling -> predict next word.
Note: Maths behind each technique is discussed in future articles, if you wanted to have more intuition behind each technique, do subscribe to teckbakers and share your love towards the articles:)
Applications Built over Transformer Architecture
BERT: Bidirectional Encoder Only model trained using masked language modelling and Next sentence prediction tasks.
T5: Encoder-Decoder Model
GPT: Unidirectional Autoregressive Decoder only model.
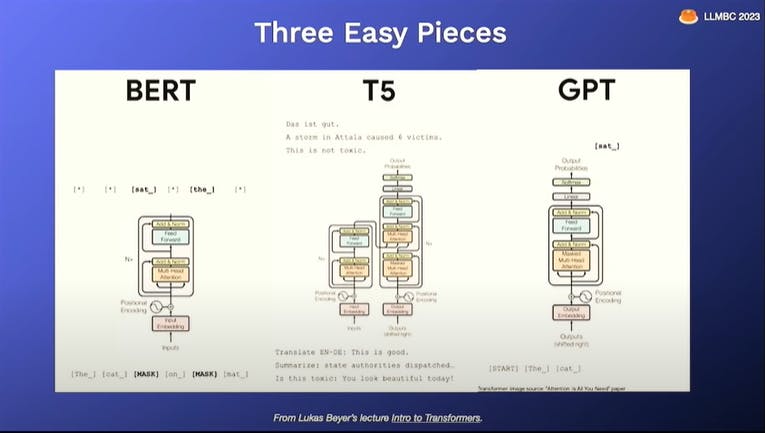
What are Foundational Models?
Large Foundational models that we see today like GPT, BARD, LLAMA, Claude are all backed by Transformers, The Training of Transformers work differently both at training time and inference time. Before diving into the details of how they are getting trained let's first understand how Foundational Models like GPT/bard/claude/mistral/DBRx are getting trained?
Foundational models: They are the large scale of neural networks trained on GB or TB data and they serve as a base or "Foundation" for multitude of applications. they can apply information it's learnt about one situation to a different situation it was not trained on. Pre-trained a foundational model, and you can teach it an entirely new task with limited labeled examples. So, right data and right fine-tuning combinely can create entirely new application.
Foundation models can be trained in three stages:
Pre-training: High quantities of training data to inform large, general-purpose models. If one has Large compute, Enough time, Large Amount of Data, Skills of neural networks and Money then, it's better to go ahead with pre-training
Fine-tuning: Addition of context-specific data to align outputs more closely with use cases. It's widely used across industries nowadays, depending upon the tasks like classification, extraction, Chatbot, Summarization etc. the dataset is getting prepared and pre-trained model is get fine-tuned specific to the task.
Inference(ICT): Incorporation of user feedback for further tuning and addition of more data as users interact with the models via plugins.
from the below image you can see how chatGPT is getting trained Pre-training -> Fine-tuning -> RLHF with PPO. How chatgpt is getting trained? if you don't now then checkout this article, inside the mind of chatgpt.

Let's discuss the working of transformers through a English to French "Machine Translation" example.
How Transformers work at training time?
Transformers as we know is made up of combination of two architectures. Encoder and Decoder.
Encoder: the sentence or question that we pass to the encoder,
first tokenize the sequence, it's an independent part and a decade of research has been done on tokenization techniques. GPT uses BPE(Byte pair encoding), Llama model uses (sentence-piece encoding) and Bloomeberg uses unigram tokenizer. In the next article i'm going to discuss about tokenization evolution and how it's crucial for performance enhancement, do subscribe to teckbakers.
Let's consider "hello my dog is cute" after tokenization converted into ["hello", "my", "dog", "is", "cute"]. into words, further these words or tokens get encoded using UTF-8 encoding. The encoded number list or sequence known as input_ids, it contains the mapping of the vocabulary(Ascii-character: utf-encoded Integer). The raw input_ids are further pass-on to the Encoder block and the whole lot of process to convert that raw vectors into context-rich vectors which contains deeper relationship between words, sentences, paragraphs and positions, discussed in Encoder part.
The output of the encoder will be a context rich embeddings for each word or token feeded into the encoder. like as we feeded 5 words, then encoder contains 5 context-rich vectors. These Vectors also know as thought vectors.
For multiple inputs during fine-tuning Batch Processing is used for which we pass batch of inputs at once in an encoder, which reduces time and increases efficiency of learning. For batch processing we add <PAD> tokens at the end of the sentence and GPT model encoded that as 101 in english vocab.
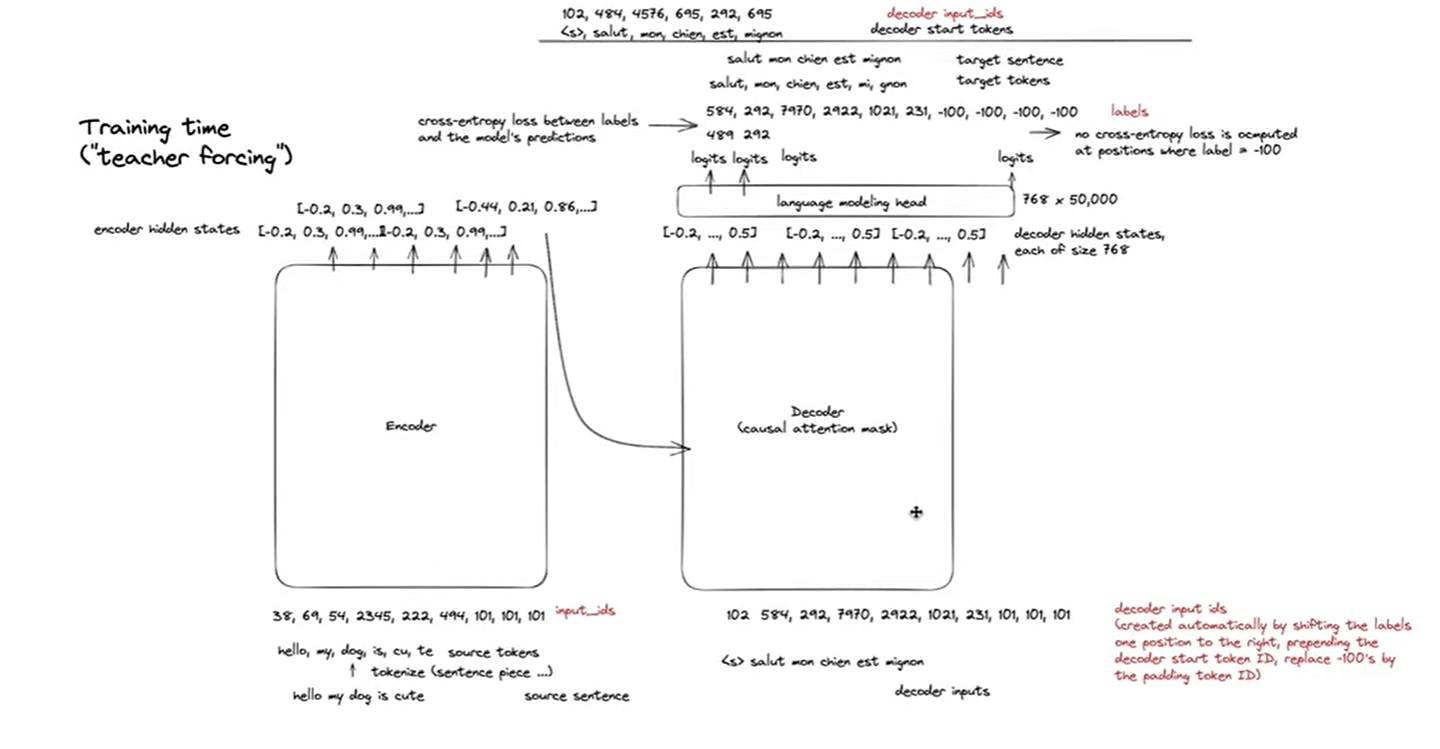
Decoder: The Decoder takes input from encoder and takes raw input_ids which are tokenized encoded vectors of french word note: during the output french tokenization, the sequence is shifted to right so as to add <S> start token into the sequence and further appends <EOS> token at the end. cuz, during fine-tuning we train the model over a labeled dataset ["hello my dog is cute", "salut mon chien est mignon"]
Hence, embedding from the encoder are decoded and converted into the raw input_ids(utf-8 encoded values), when passed through Linear Layer which contains mapping of vocabulary. Now, The decoded input_ids and raw input_ids of french words are compared to calculate cross-entropy loss and with gradient descent parameters get optimized.
The below process happens at a single timestamp at one epoch.
better illustration is shown in the diagram below.
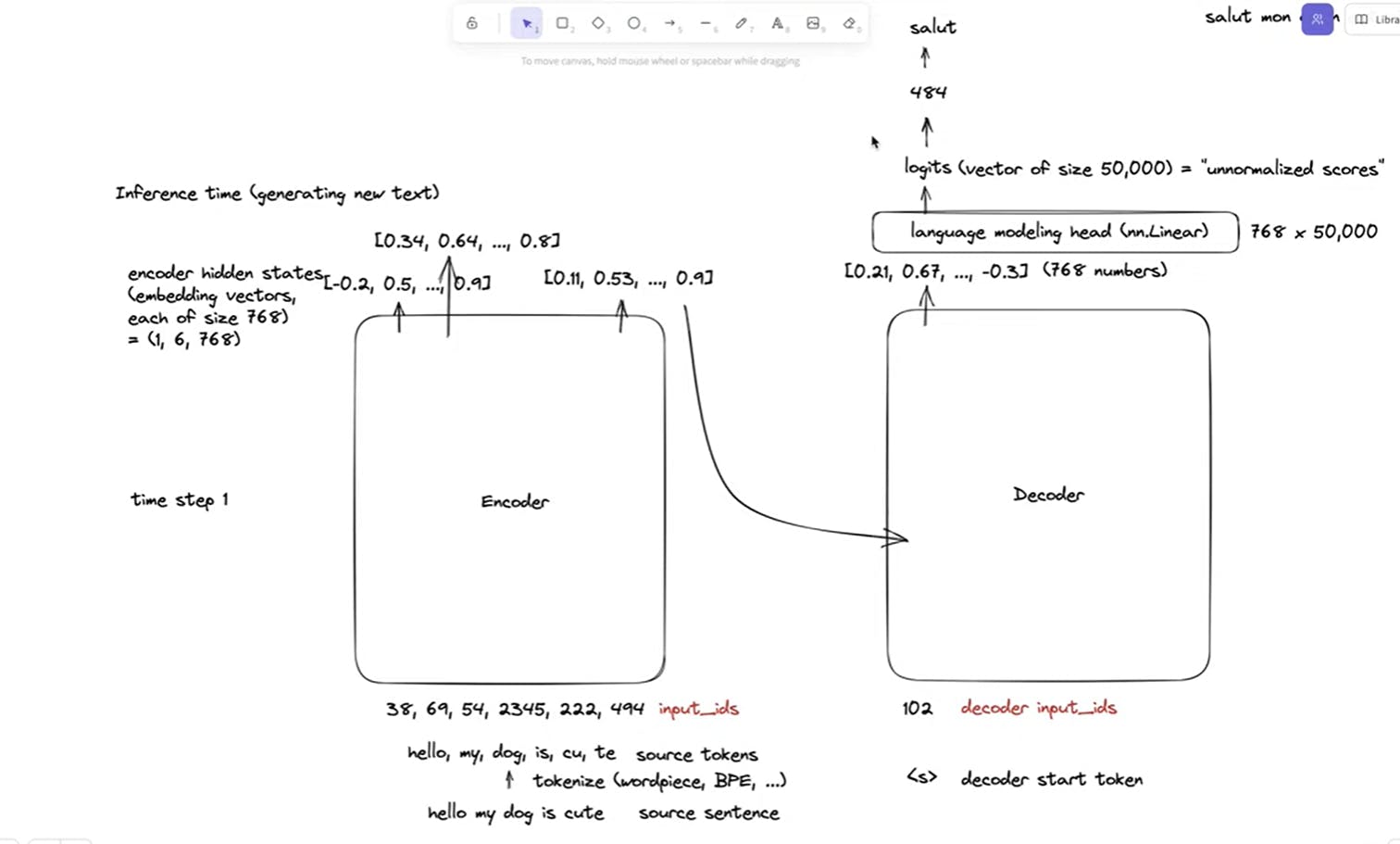
How Transformers work at Inference time?
The transformers at inference time takes single input as a prompt or query that user passes it, further it converts that into tokens -> raw input_ids -> Encoder -> Emebddings -> Decoder -> single raw output id is generated which further decoded.. the decoding process repeats until <EOD>. Hence the decoder only models are known to be auto-regressive models.
At timeStamp1 <S> token is getting feeded into the decoder, then it generates the next token salut.
TimeStep2:<S>, salut passed in the decoder and predicted next token as mon
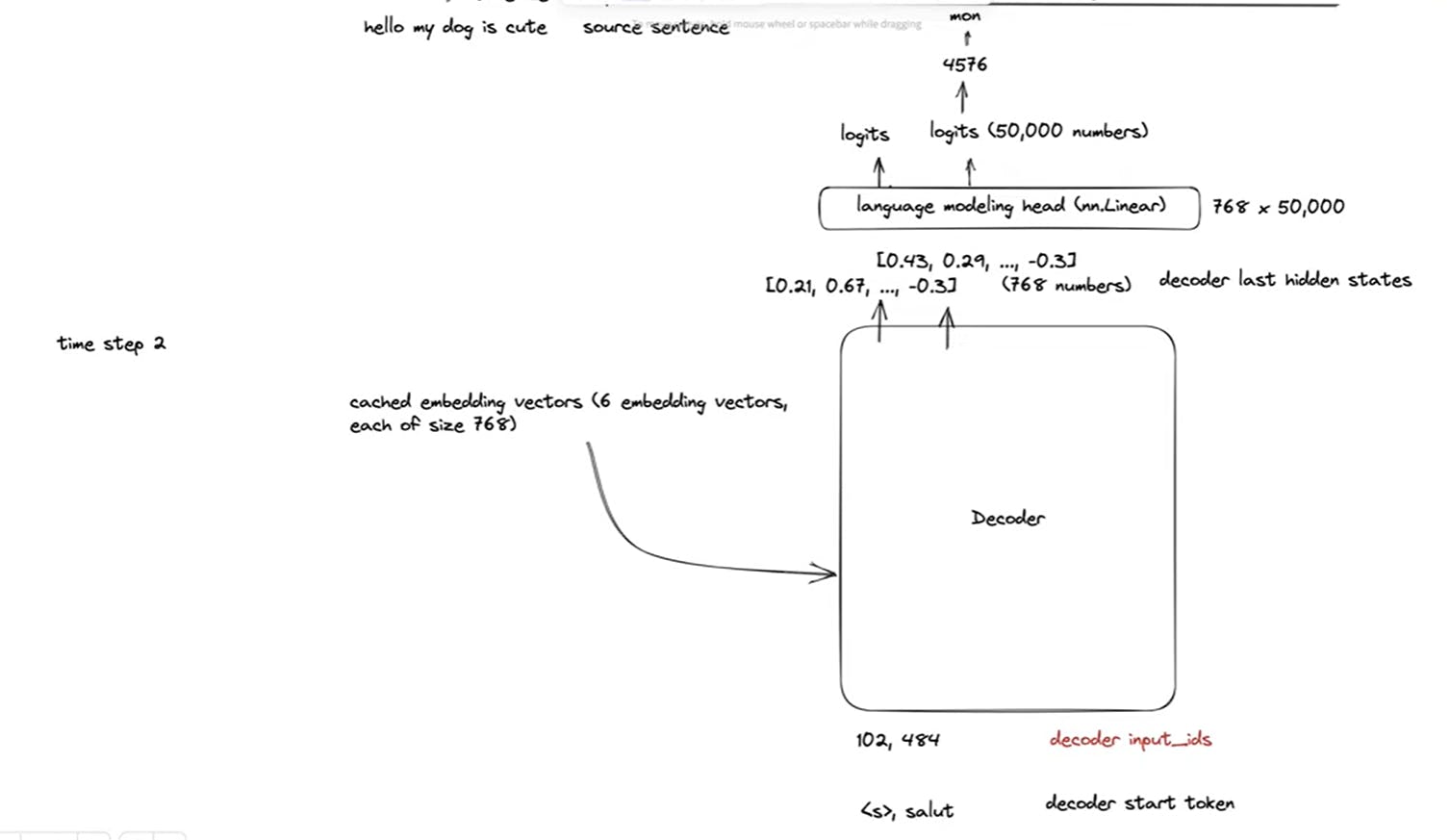
TimeStep3: <S>, salut mon passed into the docoder and predict the next word as chien
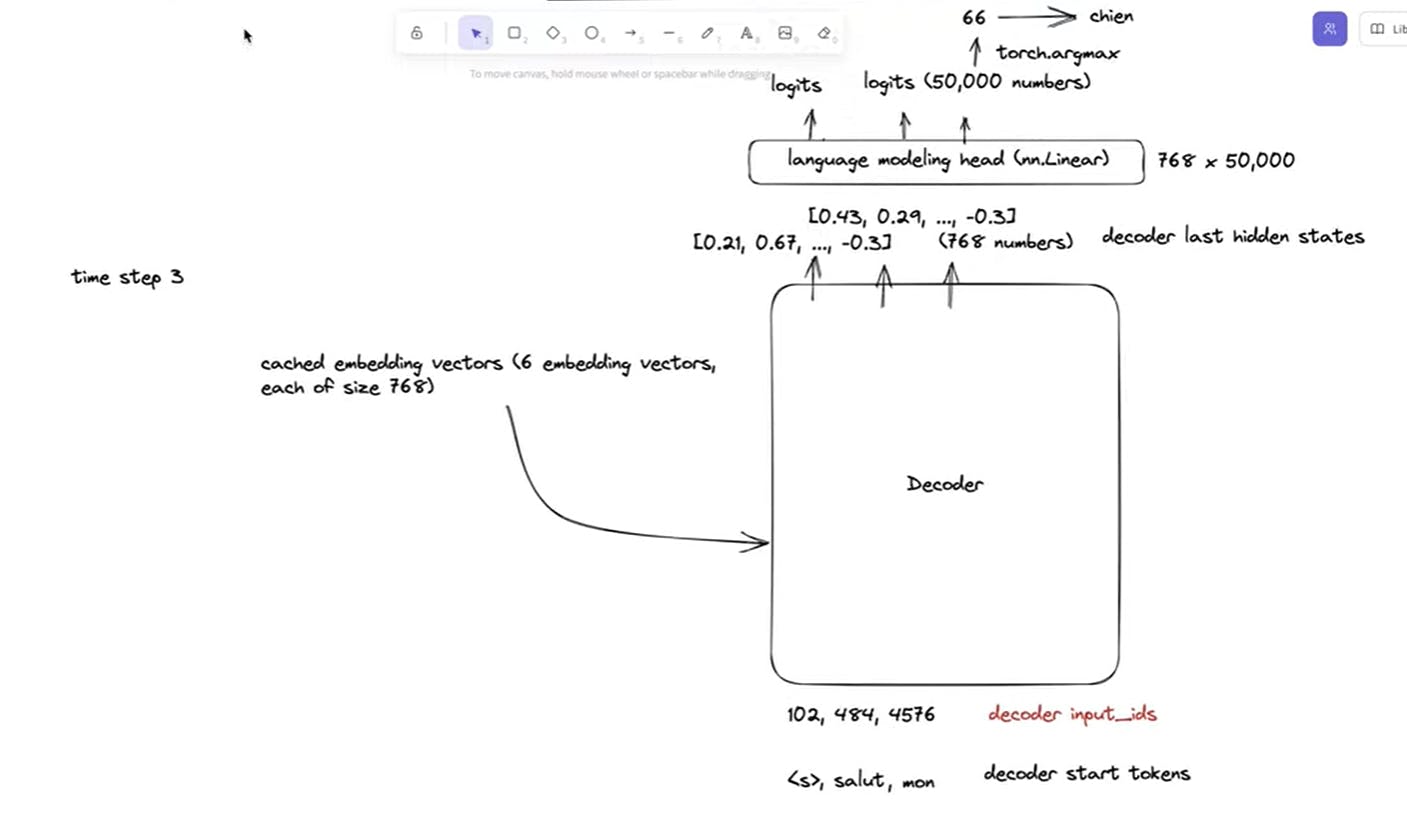
Likewise the process of predicting next tokens goes on until the decoder reach <EOS> token,and finally we get the translated sentence <s> salut mon chien est mignon
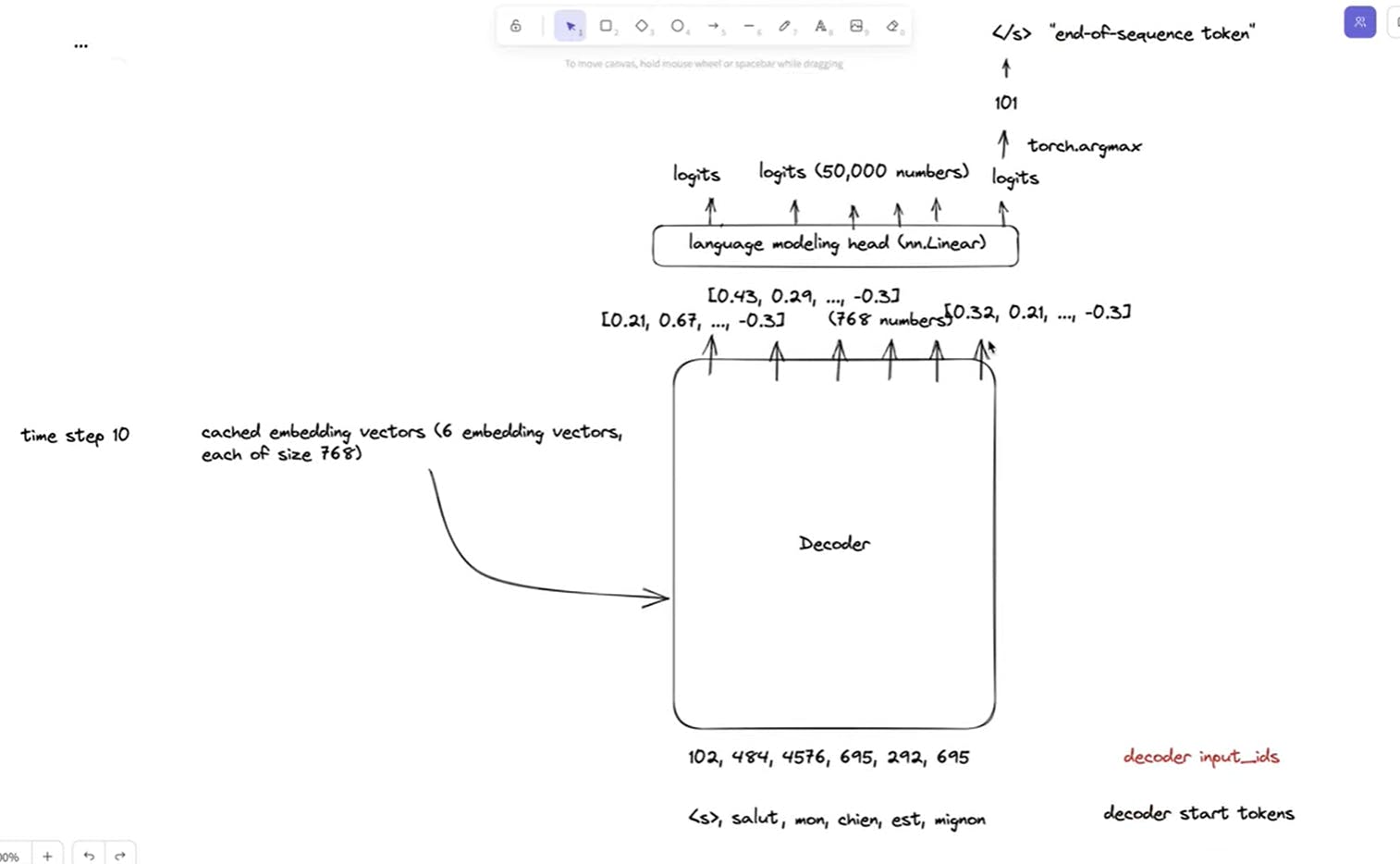
This is how the encoder-decoder works at inference time.
Bonus: Mixture of Experts by Mistral
Mixture of experts is an ensemble learning technique developed in the field of neural networks.
The idea of MoE dates back to 1991, and Google applied it to Transformer-based LLMs in 2021. In 2022, InfoQ covered Google's Image-Text MoE model LIMoE, which outperformed CLIP. Later that year, InfoQ also covered Meta's NLB-200 MoE translation model, which can translate between any of over 200 languages.
The key idea of MoE models is to replace the feed-forward layers of the Transformer block with a combination of a router plus a set of expert layers. During inference, the router in a Transformer block selects a subset of the experts to activate. In the Mixtral model, the output for that block is computed by applying the softmax function to the top two experts.
Mixtral is not just another large language model. It stands apart due to its unique architecture — a Mixture of Experts (MoE). This model features 8 “expert” models in one, utilizing a sparse MoE layer replacing some Feed-Forward layers. This design allows for efficient processing and speedy decoding, making Mixtral a highly efficient AI model.
The fine-tuned version of the model, Mistral 8x7B Instruct, was trained using DPO, instead of the RLHF technique used to train ChatGPT. This method was developed by researchers at Stanford University and "matches or improves response quality" compared to RLHF, while being much simpler to implement. DPO uses the same dataset as RLHF, a set of paired responses with one ranked higher than the other, but doesn't require creating a separate reward function for RL.
This is just the short information regarding mixture of experts but as it's such an innovative design technique, due to which a large model like mistral8x7 can be fine-tuned on google colab and the shorter inference time and it outperforms several benchmarks to Gpt-3.5 and llama-2-70B models.
And!! We reached the <EOS> 😀. You right now must have the overall idea behind what actually happens behind transformers. in the further series will go in-depth towards the implementation of each components of transformers from scratch.
Stay tuned and follow our newsletter to get daily updates and projects in the industry every week!! Connect with me on linkedin, github, kaggle.
Let's Learn and grow together:) Stay Healthy stay Happy✨. Happy Learning!!